Sign Language Recognition
Categorized under My Projects / Deep Learning tagged Lstm Last modified at:
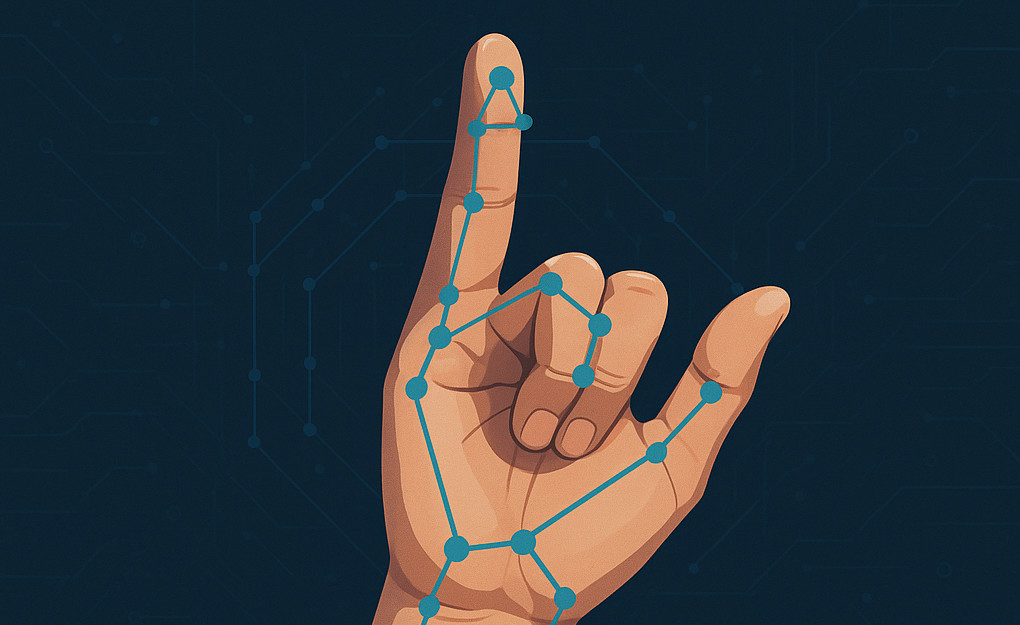
A real-time word level sign language recognition system built with Flask, MediaPipe, and deep learning.
- GitHub
- 📸 Demo
- ▶️ Inference
- Dataset
- Features
- 🔬 Features in Detail
- 🚀 How It Works
- 🔑 Tips for Better Recognition
- 🧠 Model Architecture
- Tech Stack
- 🔧 System Requirements
- 🛠️ Installation
- 📁 Project Structure
- Database Schema
- API Endpoints
- ⚠️ Troubleshooting
- Acknowledgments
A real-time sign language recognition system built with Flask, MediaPipe, and deep learning. The system can recognize word-level sign language gestures in real-time through a web interface, as well as manage a dataset of sign language videos for training.
GitHub
📸 Demo
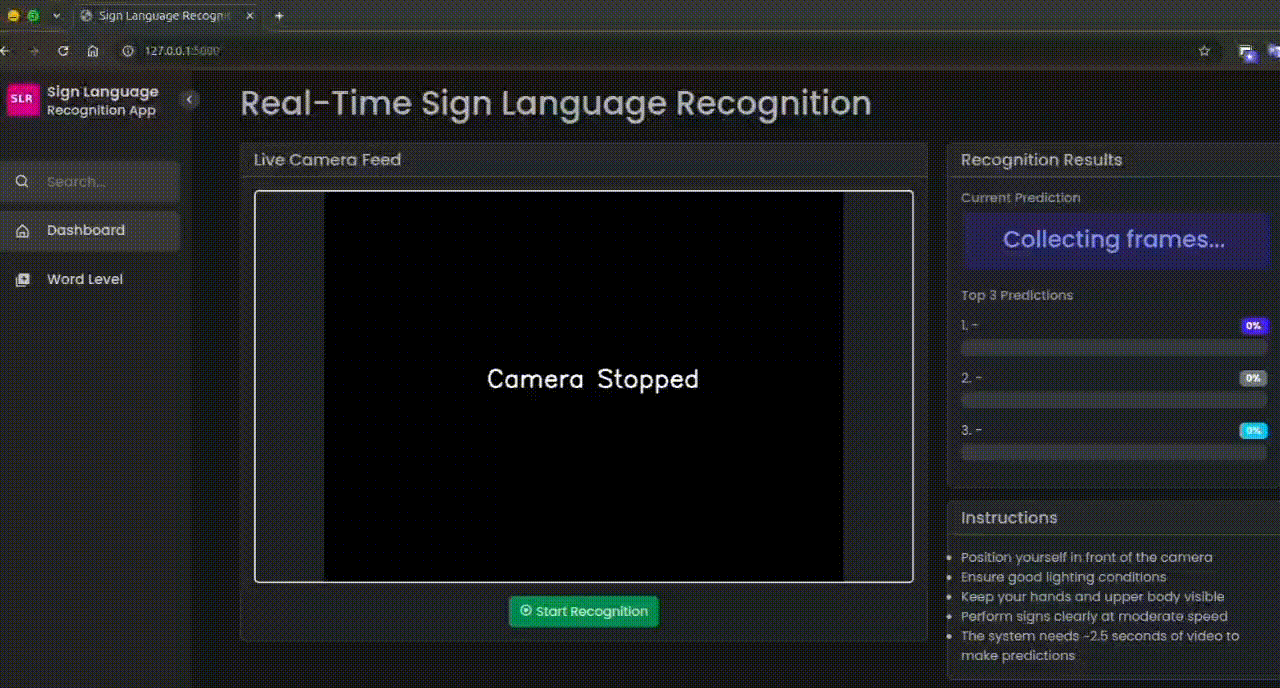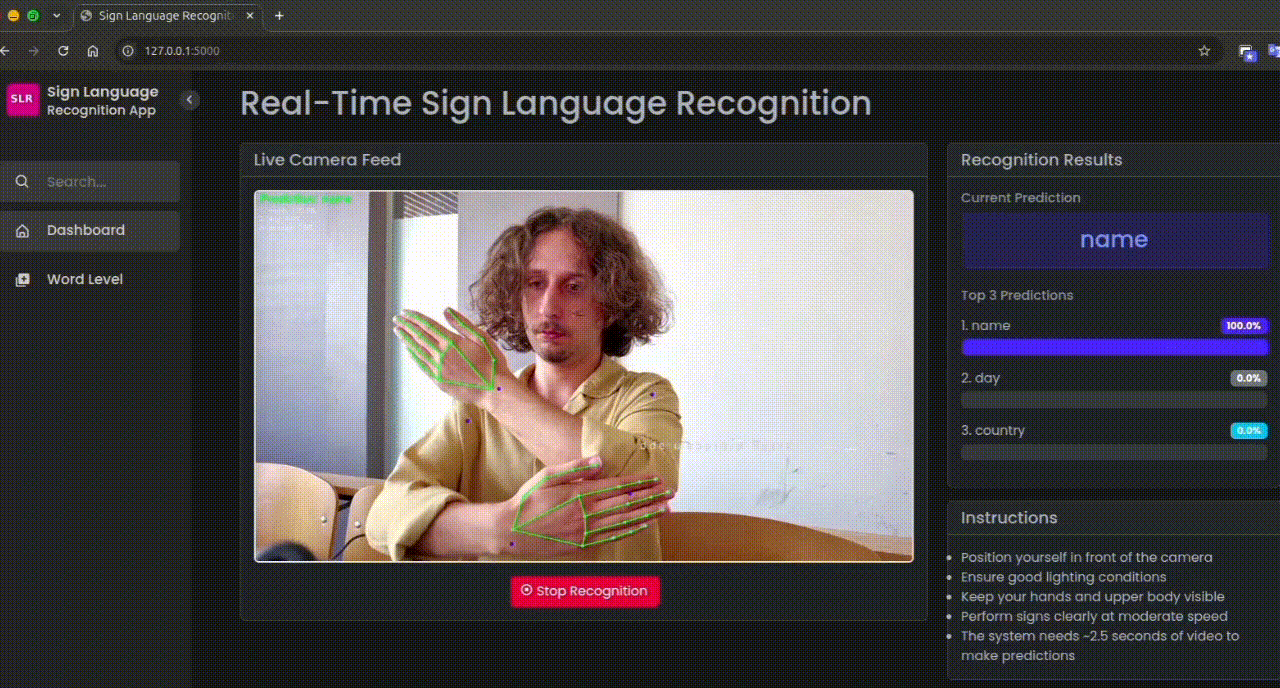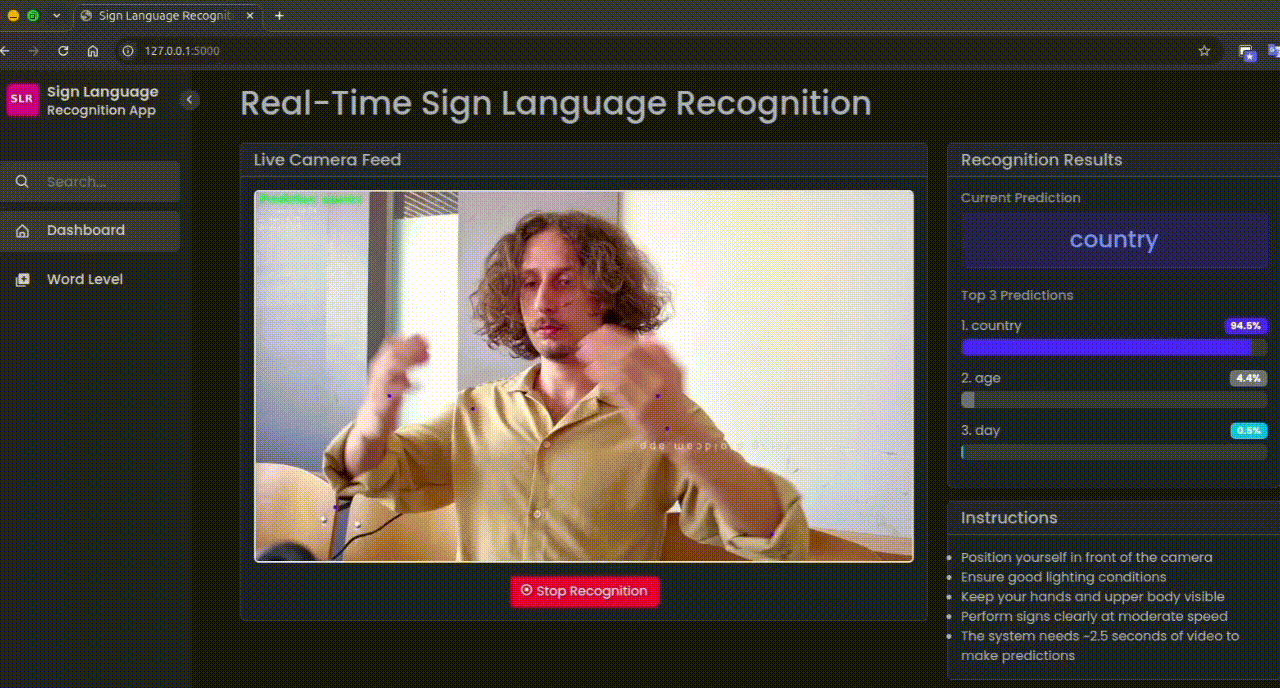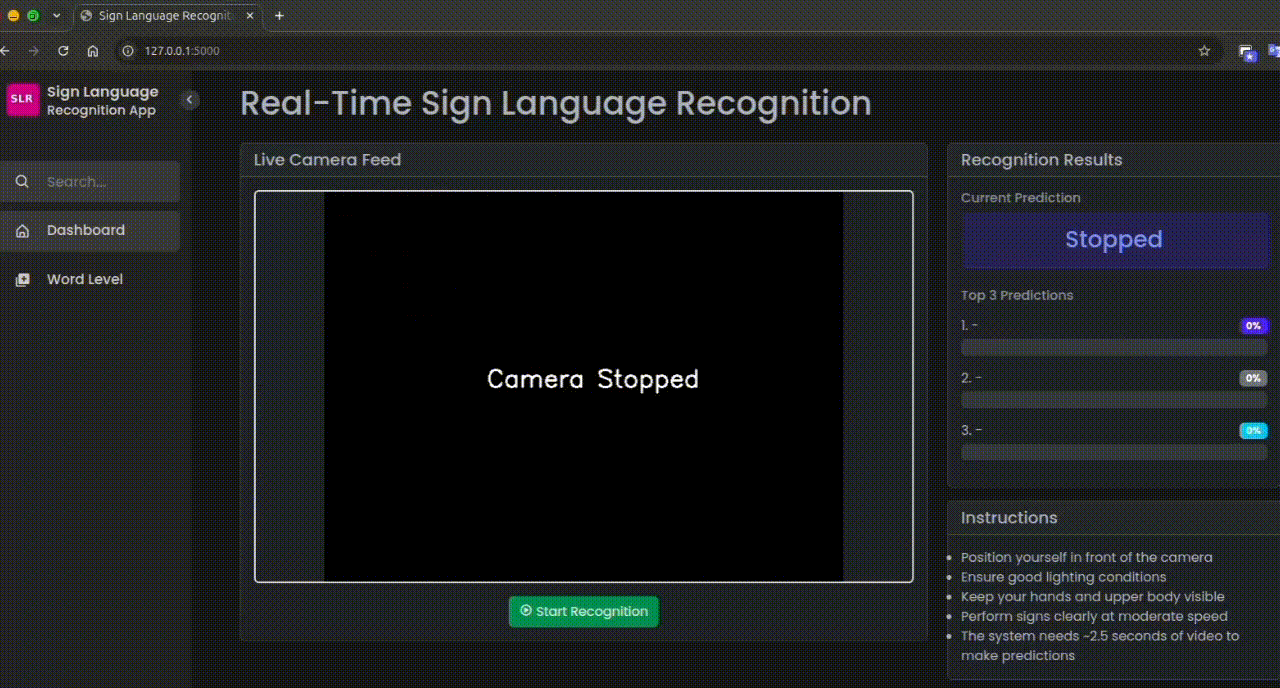
Real-time webcam feed with live sign prediction.
▶️ Inference
python real_time_inference.py
You should edit it according to the camera id on your device. cam_id = your_cam_id
Dataset
Features
- Real-time Recognition: Live sign language gesture recognition through webcam
- Modern Web Interface: Clean, responsive dashboard with real-time predictions
- Dataset Management: Tools for recording, importing, and managing sign language videos
- MediaPipe: MediaPipe landmark extraction for hands and pose
- Video Processing: Automatic landmark extraction and feature generation
- Training Pipeline: Complete pipeline for training sign language recognition models
- LSTM-based prediction: Using sliding windows
🔬 Features in Detail
Real-time Recognition
- Uses MediaPipe for hand and pose landmark detection
- LSTM model for sequence-based gesture recognition
- Live video streaming with real-time predictions
- Top-3 prediction display with confidence scores
Dataset Management
- Record videos directly through the web interface
- Import existing videos with custom labels
- Automatic landmark extraction and feature generation
- Mirror augmentation support
- Video segmentation for precise gesture isolation
Training Pipeline
- Automated feature extraction from video segments
- Standardized preprocessing pipeline
- LSTM-based deep learning model
- Performance visualization and evaluation tools
🚀 How It Works
🔹 Step 1: Capture Input
- Uses webcam feed via OpenCV.
- MediaPipe detects:
- Pose landmarks: shoulders, elbows, wrists (6 points)
- Hand landmarks: only fingertips (5 per hand)
🔹 Step 2: Extract Features
For each 0.5s window (~7–8 frames):
- Calculates mean and std of X/Y/Z positions for:
- Left & right hand fingertips
- Upper body joints
These features are stacked across 5 consecutive windows to form an LSTM input.
🔹 Step 3: Predict Word
- Preprocessed input is passed to an LSTM model.
- Top-3 predictions are shown on screen in real-time.
🔑 Tips for Better Recognition
- Lighting: Ensure good lighting conditions
- Background: Use a plain background for better landmark detection
- Distance: Stay at an appropriate distance from the camera
- Movement: Perform signs clearly and at a moderate speed
- Framing: Keep your hands and upper body visible in the frame
🧠 Model Architecture
The script uses:
app/model/sign_language_recognition.keras: LSTM model trained on sign language data- Input shape:
(5, N)where 5 = time steps, N = number of extracted features (e.g., 18–36) - Architecture: LSTM + Dense layers
- Output: Softmax over sign vocabulary
- Input shape:
app/model/scaler.pkl: StandardScaler for feature normalizationapp/model/label_encoder.pkl: LabelEncoder for class labelsapp/model/feature_order.json: Ensures features are in the correct order
Tech Stack
- Backend: Flask, Celery, Redis
- Frontend: Bootstrap 5, JavaScript
- Computer Vision: OpenCV, MediaPipe
- Machine Learning: TensorFlow, scikit-learn
- Database: SQLite with SQLAlchemy
🔧 System Requirements
- Python 3.10.12
- Redis Server
- Webcam for real-time recognition
- Modern web browser with JavaScript enabled
🛠️ Installation
- Clone the repository:
git clone https://github.com/metehanozdeniz/sign-language-recognition.git cd sign-language-recognition - Create and activate a virtual environment:
python -m venv venv source venv/bin/activate # On Windows: venv\Scripts\activate - 📦 Install dependencies:
pip install -r requirements.txt - Start Redis server:
redis-server - Run the application:
#Terminal 1: Start Celery worker
celery -A celery_worker.celery worker --loglevel=info
#Terminal 2: Start Flask application
python run.py
The application will be available at http://localhost:5000
📁 Project Structure
sign-language-recognition/
├── app/
│ ├── model/ # Trained models and preprocessing files
│ ├── static/ # Static files (JS, CSS, images)
│ ├── templates/ # HTML templates
│ ├── utils/ # Utility modules
│ ├── videos/ # Stored video files
│ ├── __init__.py # App initialization
│ ├── config.py # Configuration settings
│ ├── models.py # Database models
│ ├── routes.py # Route handlers
│ └── tasks.py # Celery tasks
├── venv/ # Virtual environment
├── celery_worker.py # Celery worker configuration
├── requirements.txt # Project dependencies
├── run.py # Application entry point
└── train.ipynb # Model training script
Database Schema
Video
- Stores video metadata and file paths
- Tracks video duration and creation time
- Links to landmarks and features
FrameLandmark
- Stores extracted MediaPipe landmarks
- Supports both hand and pose landmarks
- Maintains frame-level temporal information
VideoFeature
- Stores processed features for model training
- Supports windowed feature extraction
- Links features to source videos
API Endpoints
Recognition
/video_feed- Live video stream/current_predictions- Real-time prediction results/toggle_recognition- Start/stop recognition/recognition_status- Current recognition state
Dataset Management
/record- Video recording interface/import- Video import interface/gallery- Video gallery and management/process_video- Landmark extraction endpoint/task_status/<task_id>- Processing status endpoint
⚠️ Troubleshooting
If you encounter issues:
- Check that your webcam is working and accessible
- Verify all model files are present in
app/model/ - Ensure MediaPipe can detect your hands and pose
- Try adjusting the detection confidence thresholds in the code
Acknowledgments
- MediaPipe for providing the pose and hand landmark detection models
- TensorFlow and Keras for the deep learning framework
- Flask team for the excellent web framework