Brain Tumor Classification
This project aimed to build a Convolutional Neural Network based deep learning model to first identify brain tumors and then classify them as Benign Tumors, Malignant Tumors or Pituitary Tumors.
- Source Code
- Dataset
- Introduction
- Context
- Methodology
- Import Libraries
- Configure Tensorboard
- Set Hyperparameters
- Data Preprocessing
- Build Model
- Start Tensorboard
- Fit the Model
- Evaluate the model
- visualize training history
- Save the Model
- Load the Model
- Predict
This project aimed to build a Convolutional Neural Network based deep learning model to first identify brain tumors and then classify them as Benign Tumors, Malignant Tumors or Pituitary Tumors.
Source Code
Dataset
Introduction
Brain Tumors are classified as: Benign Tumor, Malignant Tumor, Pituitary Tumor, etc. Proper treatment, planning, and accurate diagnostics should be implemented to improve the life expectancy of the patients. The best technique to detect brain tumors is Magnetic Resonance Imaging (MRI). A huge amount of image data is generated through the scans. These images are examined by the radiologist. A manual examination can be error-prone due to the level of complexities involved in brain tumors and their properties.
Application of automated classification techniques using Machine Learning(ML) and Artificial Intelligence(AI)has consistently shown higher accuracy than manual classification. Hence, proposing a system performing detection and classification by using Deep Learning Algorithms using ConvolutionNeural Network (CNN), Artificial Neural Network (ANN), and TransferLearning (TL) would be helpful to doctors all around the world.
Context
Brain Tumors are complex. There are a lot of abnormalities in the sizes and location of the brain tumor(s). This makes it really difficult for complete understanding of the nature of the tumor. Also, a professional Neurosurgeon is required for MRI analysis. Often times in developing countries the lack of skillful doctors and lack of knowledge about tumors makes it really challenging and time-consuming to generate reports from MRI’. So an automated system on Cloud can solve this problem.
Methodology
Transfer Learning
Transfer learning is a deep learning technique where we use a pre-defined and pre-trained neural network and train it again on the current data set. We used ResNet50 model in this project.
Import Libraries
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, GlobalAveragePooling2D, Dense, Flatten, Dropout
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import TensorBoard, EarlyStopping, ReduceLROnPlateau, ModelCheckpoint
from tensorflow.keras.applications import ResNet50
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.models import load_model
from sklearn.metrics import classification_report, accuracy_score, confusion_matrix
from sklearn.model_selection import train_test_split
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import cv2
import os
Configure Tensorboard
log_dir = "log/resnet50/" + tf.timestamp().numpy().astype(str)
tensorboard = TensorBoard(log_dir=log_dir, histogram_freq=1)
# Clear any logs from previous runs
!rm -rf ./log/resnet50/
Set Hyperparameters
X_train = []
Y_train = []
labels = ['glioma_tumor','meningioma_tumor','no_tumor','pituitary_tumor']
IMG_SIZE = 224
INPUT_SHAPE = (IMG_SIZE, IMG_SIZE, 3)
CLASSES = len(labels)
EPOCH = 20
BATCH_SIZE = 4
Data Preprocessing
for i in labels:
folderPath = os.path.join('dataset/Training',i)
for j in os.listdir(folderPath):
img = cv2.imread(os.path.join(folderPath,j))
img = cv2.resize(img,(IMG_SIZE,IMG_SIZE))
X_train.append(img)
Y_train.append(i)
for i in labels:
folderPath = os.path.join('dataset/Testing',i)
for j in os.listdir(folderPath):
img = cv2.imread(os.path.join(folderPath,j))
img = cv2.resize(img,(IMG_SIZE,IMG_SIZE))
X_train.append(img)
Y_train.append(i)
X_train = np.array(X_train)
Y_train = np.array(Y_train)
print('x train shape : ',X_train.shape)
print('y train shape : ', Y_train.shape)
x train shape : (3264, 224, 224, 3)
y train shape : (3264,)
Train Test Split
X_train, X_test, Y_train, Y_test = train_test_split(X_train, Y_train, test_size=0.2, random_state=42)
One Hot Encoding
y_train_new = []
for i in Y_train:
y_train_new.append(labels.index(i))
Y_train=y_train_new
Y_train = tf.keras.utils.to_categorical(Y_train)
y_test_new = []
for i in Y_test:
y_test_new.append(labels.index(i))
Y_test=y_test_new
Y_test = tf.keras.utils.to_categorical(Y_test)
Build Model
Download ResNet50 Model
base_model = ResNet50(weights='imagenet',
include_top=False,
input_shape=INPUT_SHAPE)
base_model.summary()
Model: "resnet50"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 224, 224, 3)] 0 []
conv1_pad (ZeroPadding2D) (None, 230, 230, 3) 0 ['input_1[0][0]']
conv1_conv (Conv2D) (None, 112, 112, 64) 9472 ['conv1_pad[0][0]']
conv1_bn (BatchNormalizati (None, 112, 112, 64) 256 ['conv1_conv[0][0]']
on)
conv1_relu (Activation) (None, 112, 112, 64) 0 ['conv1_bn[0][0]']
pool1_pad (ZeroPadding2D) (None, 114, 114, 64) 0 ['conv1_relu[0][0]']
pool1_pool (MaxPooling2D) (None, 56, 56, 64) 0 ['pool1_pad[0][0]']
conv2_block1_1_conv (Conv2 (None, 56, 56, 64) 4160 ['pool1_pool[0][0]']
D)
conv2_block1_1_bn (BatchNo (None, 56, 56, 64) 256 ['conv2_block1_1_conv[0][0]']
rmalization)
conv2_block1_1_relu (Activ (None, 56, 56, 64) 0 ['conv2_block1_1_bn[0][0]']
ation)
conv2_block1_2_conv (Conv2 (None, 56, 56, 64) 36928 ['conv2_block1_1_relu[0][0]']
D)
conv2_block1_2_bn (BatchNo (None, 56, 56, 64) 256 ['conv2_block1_2_conv[0][0]']
rmalization)
conv2_block1_2_relu (Activ (None, 56, 56, 64) 0 ['conv2_block1_2_bn[0][0]']
ation)
conv2_block1_0_conv (Conv2 (None, 56, 56, 256) 16640 ['pool1_pool[0][0]']
D)
conv2_block1_3_conv (Conv2 (None, 56, 56, 256) 16640 ['conv2_block1_2_relu[0][0]']
D)
conv2_block1_0_bn (BatchNo (None, 56, 56, 256) 1024 ['conv2_block1_0_conv[0][0]']
rmalization)
conv2_block1_3_bn (BatchNo (None, 56, 56, 256) 1024 ['conv2_block1_3_conv[0][0]']
rmalization)
conv2_block1_add (Add) (None, 56, 56, 256) 0 ['conv2_block1_0_bn[0][0]',
'conv2_block1_3_bn[0][0]']
conv2_block1_out (Activati (None, 56, 56, 256) 0 ['conv2_block1_add[0][0]']
on)
conv2_block2_1_conv (Conv2 (None, 56, 56, 64) 16448 ['conv2_block1_out[0][0]']
D)
conv2_block2_1_bn (BatchNo (None, 56, 56, 64) 256 ['conv2_block2_1_conv[0][0]']
rmalization)
conv2_block2_1_relu (Activ (None, 56, 56, 64) 0 ['conv2_block2_1_bn[0][0]']
ation)
conv2_block2_2_conv (Conv2 (None, 56, 56, 64) 36928 ['conv2_block2_1_relu[0][0]']
D)
conv2_block2_2_bn (BatchNo (None, 56, 56, 64) 256 ['conv2_block2_2_conv[0][0]']
rmalization)
conv2_block2_2_relu (Activ (None, 56, 56, 64) 0 ['conv2_block2_2_bn[0][0]']
ation)
conv2_block2_3_conv (Conv2 (None, 56, 56, 256) 16640 ['conv2_block2_2_relu[0][0]']
D)
conv2_block2_3_bn (BatchNo (None, 56, 56, 256) 1024 ['conv2_block2_3_conv[0][0]']
rmalization)
conv2_block2_add (Add) (None, 56, 56, 256) 0 ['conv2_block1_out[0][0]',
'conv2_block2_3_bn[0][0]']
conv2_block2_out (Activati (None, 56, 56, 256) 0 ['conv2_block2_add[0][0]']
on)
conv2_block3_1_conv (Conv2 (None, 56, 56, 64) 16448 ['conv2_block2_out[0][0]']
D)
conv2_block3_1_bn (BatchNo (None, 56, 56, 64) 256 ['conv2_block3_1_conv[0][0]']
rmalization)
conv2_block3_1_relu (Activ (None, 56, 56, 64) 0 ['conv2_block3_1_bn[0][0]']
ation)
conv2_block3_2_conv (Conv2 (None, 56, 56, 64) 36928 ['conv2_block3_1_relu[0][0]']
D)
conv2_block3_2_bn (BatchNo (None, 56, 56, 64) 256 ['conv2_block3_2_conv[0][0]']
rmalization)
conv2_block3_2_relu (Activ (None, 56, 56, 64) 0 ['conv2_block3_2_bn[0][0]']
ation)
conv2_block3_3_conv (Conv2 (None, 56, 56, 256) 16640 ['conv2_block3_2_relu[0][0]']
D)
conv2_block3_3_bn (BatchNo (None, 56, 56, 256) 1024 ['conv2_block3_3_conv[0][0]']
rmalization)
conv2_block3_add (Add) (None, 56, 56, 256) 0 ['conv2_block2_out[0][0]',
'conv2_block3_3_bn[0][0]']
conv2_block3_out (Activati (None, 56, 56, 256) 0 ['conv2_block3_add[0][0]']
on)
conv3_block1_1_conv (Conv2 (None, 28, 28, 128) 32896 ['conv2_block3_out[0][0]']
D)
conv3_block1_1_bn (BatchNo (None, 28, 28, 128) 512 ['conv3_block1_1_conv[0][0]']
rmalization)
conv3_block1_1_relu (Activ (None, 28, 28, 128) 0 ['conv3_block1_1_bn[0][0]']
ation)
conv3_block1_2_conv (Conv2 (None, 28, 28, 128) 147584 ['conv3_block1_1_relu[0][0]']
D)
conv3_block1_2_bn (BatchNo (None, 28, 28, 128) 512 ['conv3_block1_2_conv[0][0]']
rmalization)
conv3_block1_2_relu (Activ (None, 28, 28, 128) 0 ['conv3_block1_2_bn[0][0]']
ation)
conv3_block1_0_conv (Conv2 (None, 28, 28, 512) 131584 ['conv2_block3_out[0][0]']
D)
conv3_block1_3_conv (Conv2 (None, 28, 28, 512) 66048 ['conv3_block1_2_relu[0][0]']
D)
conv3_block1_0_bn (BatchNo (None, 28, 28, 512) 2048 ['conv3_block1_0_conv[0][0]']
rmalization)
conv3_block1_3_bn (BatchNo (None, 28, 28, 512) 2048 ['conv3_block1_3_conv[0][0]']
rmalization)
conv3_block1_add (Add) (None, 28, 28, 512) 0 ['conv3_block1_0_bn[0][0]',
'conv3_block1_3_bn[0][0]']
conv3_block1_out (Activati (None, 28, 28, 512) 0 ['conv3_block1_add[0][0]']
on)
conv3_block2_1_conv (Conv2 (None, 28, 28, 128) 65664 ['conv3_block1_out[0][0]']
D)
conv3_block2_1_bn (BatchNo (None, 28, 28, 128) 512 ['conv3_block2_1_conv[0][0]']
rmalization)
conv3_block2_1_relu (Activ (None, 28, 28, 128) 0 ['conv3_block2_1_bn[0][0]']
ation)
conv3_block2_2_conv (Conv2 (None, 28, 28, 128) 147584 ['conv3_block2_1_relu[0][0]']
D)
conv3_block2_2_bn (BatchNo (None, 28, 28, 128) 512 ['conv3_block2_2_conv[0][0]']
rmalization)
conv3_block2_2_relu (Activ (None, 28, 28, 128) 0 ['conv3_block2_2_bn[0][0]']
ation)
conv3_block2_3_conv (Conv2 (None, 28, 28, 512) 66048 ['conv3_block2_2_relu[0][0]']
D)
conv3_block2_3_bn (BatchNo (None, 28, 28, 512) 2048 ['conv3_block2_3_conv[0][0]']
rmalization)
conv3_block2_add (Add) (None, 28, 28, 512) 0 ['conv3_block1_out[0][0]',
'conv3_block2_3_bn[0][0]']
conv3_block2_out (Activati (None, 28, 28, 512) 0 ['conv3_block2_add[0][0]']
on)
conv3_block3_1_conv (Conv2 (None, 28, 28, 128) 65664 ['conv3_block2_out[0][0]']
D)
conv3_block3_1_bn (BatchNo (None, 28, 28, 128) 512 ['conv3_block3_1_conv[0][0]']
rmalization)
conv3_block3_1_relu (Activ (None, 28, 28, 128) 0 ['conv3_block3_1_bn[0][0]']
ation)
conv3_block3_2_conv (Conv2 (None, 28, 28, 128) 147584 ['conv3_block3_1_relu[0][0]']
D)
conv3_block3_2_bn (BatchNo (None, 28, 28, 128) 512 ['conv3_block3_2_conv[0][0]']
rmalization)
conv3_block3_2_relu (Activ (None, 28, 28, 128) 0 ['conv3_block3_2_bn[0][0]']
ation)
conv3_block3_3_conv (Conv2 (None, 28, 28, 512) 66048 ['conv3_block3_2_relu[0][0]']
D)
conv3_block3_3_bn (BatchNo (None, 28, 28, 512) 2048 ['conv3_block3_3_conv[0][0]']
rmalization)
conv3_block3_add (Add) (None, 28, 28, 512) 0 ['conv3_block2_out[0][0]',
'conv3_block3_3_bn[0][0]']
conv3_block3_out (Activati (None, 28, 28, 512) 0 ['conv3_block3_add[0][0]']
on)
conv3_block4_1_conv (Conv2 (None, 28, 28, 128) 65664 ['conv3_block3_out[0][0]']
D)
conv3_block4_1_bn (BatchNo (None, 28, 28, 128) 512 ['conv3_block4_1_conv[0][0]']
rmalization)
conv3_block4_1_relu (Activ (None, 28, 28, 128) 0 ['conv3_block4_1_bn[0][0]']
ation)
conv3_block4_2_conv (Conv2 (None, 28, 28, 128) 147584 ['conv3_block4_1_relu[0][0]']
D)
conv3_block4_2_bn (BatchNo (None, 28, 28, 128) 512 ['conv3_block4_2_conv[0][0]']
rmalization)
conv3_block4_2_relu (Activ (None, 28, 28, 128) 0 ['conv3_block4_2_bn[0][0]']
ation)
conv3_block4_3_conv (Conv2 (None, 28, 28, 512) 66048 ['conv3_block4_2_relu[0][0]']
D)
conv3_block4_3_bn (BatchNo (None, 28, 28, 512) 2048 ['conv3_block4_3_conv[0][0]']
rmalization)
conv3_block4_add (Add) (None, 28, 28, 512) 0 ['conv3_block3_out[0][0]',
'conv3_block4_3_bn[0][0]']
conv3_block4_out (Activati (None, 28, 28, 512) 0 ['conv3_block4_add[0][0]']
on)
conv4_block1_1_conv (Conv2 (None, 14, 14, 256) 131328 ['conv3_block4_out[0][0]']
D)
conv4_block1_1_bn (BatchNo (None, 14, 14, 256) 1024 ['conv4_block1_1_conv[0][0]']
rmalization)
conv4_block1_1_relu (Activ (None, 14, 14, 256) 0 ['conv4_block1_1_bn[0][0]']
ation)
conv4_block1_2_conv (Conv2 (None, 14, 14, 256) 590080 ['conv4_block1_1_relu[0][0]']
D)
conv4_block1_2_bn (BatchNo (None, 14, 14, 256) 1024 ['conv4_block1_2_conv[0][0]']
rmalization)
conv4_block1_2_relu (Activ (None, 14, 14, 256) 0 ['conv4_block1_2_bn[0][0]']
ation)
conv4_block1_0_conv (Conv2 (None, 14, 14, 1024) 525312 ['conv3_block4_out[0][0]']
D)
conv4_block1_3_conv (Conv2 (None, 14, 14, 1024) 263168 ['conv4_block1_2_relu[0][0]']
D)
conv4_block1_0_bn (BatchNo (None, 14, 14, 1024) 4096 ['conv4_block1_0_conv[0][0]']
rmalization)
conv4_block1_3_bn (BatchNo (None, 14, 14, 1024) 4096 ['conv4_block1_3_conv[0][0]']
rmalization)
conv4_block1_add (Add) (None, 14, 14, 1024) 0 ['conv4_block1_0_bn[0][0]',
'conv4_block1_3_bn[0][0]']
conv4_block1_out (Activati (None, 14, 14, 1024) 0 ['conv4_block1_add[0][0]']
on)
conv4_block2_1_conv (Conv2 (None, 14, 14, 256) 262400 ['conv4_block1_out[0][0]']
D)
conv4_block2_1_bn (BatchNo (None, 14, 14, 256) 1024 ['conv4_block2_1_conv[0][0]']
rmalization)
conv4_block2_1_relu (Activ (None, 14, 14, 256) 0 ['conv4_block2_1_bn[0][0]']
ation)
conv4_block2_2_conv (Conv2 (None, 14, 14, 256) 590080 ['conv4_block2_1_relu[0][0]']
D)
conv4_block2_2_bn (BatchNo (None, 14, 14, 256) 1024 ['conv4_block2_2_conv[0][0]']
rmalization)
conv4_block2_2_relu (Activ (None, 14, 14, 256) 0 ['conv4_block2_2_bn[0][0]']
ation)
conv4_block2_3_conv (Conv2 (None, 14, 14, 1024) 263168 ['conv4_block2_2_relu[0][0]']
D)
conv4_block2_3_bn (BatchNo (None, 14, 14, 1024) 4096 ['conv4_block2_3_conv[0][0]']
rmalization)
conv4_block2_add (Add) (None, 14, 14, 1024) 0 ['conv4_block1_out[0][0]',
'conv4_block2_3_bn[0][0]']
conv4_block2_out (Activati (None, 14, 14, 1024) 0 ['conv4_block2_add[0][0]']
on)
conv4_block3_1_conv (Conv2 (None, 14, 14, 256) 262400 ['conv4_block2_out[0][0]']
D)
conv4_block3_1_bn (BatchNo (None, 14, 14, 256) 1024 ['conv4_block3_1_conv[0][0]']
rmalization)
conv4_block3_1_relu (Activ (None, 14, 14, 256) 0 ['conv4_block3_1_bn[0][0]']
ation)
conv4_block3_2_conv (Conv2 (None, 14, 14, 256) 590080 ['conv4_block3_1_relu[0][0]']
D)
conv4_block3_2_bn (BatchNo (None, 14, 14, 256) 1024 ['conv4_block3_2_conv[0][0]']
rmalization)
conv4_block3_2_relu (Activ (None, 14, 14, 256) 0 ['conv4_block3_2_bn[0][0]']
ation)
conv4_block3_3_conv (Conv2 (None, 14, 14, 1024) 263168 ['conv4_block3_2_relu[0][0]']
D)
conv4_block3_3_bn (BatchNo (None, 14, 14, 1024) 4096 ['conv4_block3_3_conv[0][0]']
rmalization)
conv4_block3_add (Add) (None, 14, 14, 1024) 0 ['conv4_block2_out[0][0]',
'conv4_block3_3_bn[0][0]']
conv4_block3_out (Activati (None, 14, 14, 1024) 0 ['conv4_block3_add[0][0]']
on)
conv4_block4_1_conv (Conv2 (None, 14, 14, 256) 262400 ['conv4_block3_out[0][0]']
D)
conv4_block4_1_bn (BatchNo (None, 14, 14, 256) 1024 ['conv4_block4_1_conv[0][0]']
rmalization)
conv4_block4_1_relu (Activ (None, 14, 14, 256) 0 ['conv4_block4_1_bn[0][0]']
ation)
conv4_block4_2_conv (Conv2 (None, 14, 14, 256) 590080 ['conv4_block4_1_relu[0][0]']
D)
conv4_block4_2_bn (BatchNo (None, 14, 14, 256) 1024 ['conv4_block4_2_conv[0][0]']
rmalization)
conv4_block4_2_relu (Activ (None, 14, 14, 256) 0 ['conv4_block4_2_bn[0][0]']
ation)
conv4_block4_3_conv (Conv2 (None, 14, 14, 1024) 263168 ['conv4_block4_2_relu[0][0]']
D)
conv4_block4_3_bn (BatchNo (None, 14, 14, 1024) 4096 ['conv4_block4_3_conv[0][0]']
rmalization)
conv4_block4_add (Add) (None, 14, 14, 1024) 0 ['conv4_block3_out[0][0]',
'conv4_block4_3_bn[0][0]']
conv4_block4_out (Activati (None, 14, 14, 1024) 0 ['conv4_block4_add[0][0]']
on)
conv4_block5_1_conv (Conv2 (None, 14, 14, 256) 262400 ['conv4_block4_out[0][0]']
D)
conv4_block5_1_bn (BatchNo (None, 14, 14, 256) 1024 ['conv4_block5_1_conv[0][0]']
rmalization)
conv4_block5_1_relu (Activ (None, 14, 14, 256) 0 ['conv4_block5_1_bn[0][0]']
ation)
conv4_block5_2_conv (Conv2 (None, 14, 14, 256) 590080 ['conv4_block5_1_relu[0][0]']
D)
conv4_block5_2_bn (BatchNo (None, 14, 14, 256) 1024 ['conv4_block5_2_conv[0][0]']
rmalization)
conv4_block5_2_relu (Activ (None, 14, 14, 256) 0 ['conv4_block5_2_bn[0][0]']
ation)
conv4_block5_3_conv (Conv2 (None, 14, 14, 1024) 263168 ['conv4_block5_2_relu[0][0]']
D)
conv4_block5_3_bn (BatchNo (None, 14, 14, 1024) 4096 ['conv4_block5_3_conv[0][0]']
rmalization)
conv4_block5_add (Add) (None, 14, 14, 1024) 0 ['conv4_block4_out[0][0]',
'conv4_block5_3_bn[0][0]']
conv4_block5_out (Activati (None, 14, 14, 1024) 0 ['conv4_block5_add[0][0]']
on)
conv4_block6_1_conv (Conv2 (None, 14, 14, 256) 262400 ['conv4_block5_out[0][0]']
D)
conv4_block6_1_bn (BatchNo (None, 14, 14, 256) 1024 ['conv4_block6_1_conv[0][0]']
rmalization)
conv4_block6_1_relu (Activ (None, 14, 14, 256) 0 ['conv4_block6_1_bn[0][0]']
ation)
conv4_block6_2_conv (Conv2 (None, 14, 14, 256) 590080 ['conv4_block6_1_relu[0][0]']
D)
conv4_block6_2_bn (BatchNo (None, 14, 14, 256) 1024 ['conv4_block6_2_conv[0][0]']
rmalization)
conv4_block6_2_relu (Activ (None, 14, 14, 256) 0 ['conv4_block6_2_bn[0][0]']
ation)
conv4_block6_3_conv (Conv2 (None, 14, 14, 1024) 263168 ['conv4_block6_2_relu[0][0]']
D)
conv4_block6_3_bn (BatchNo (None, 14, 14, 1024) 4096 ['conv4_block6_3_conv[0][0]']
rmalization)
conv4_block6_add (Add) (None, 14, 14, 1024) 0 ['conv4_block5_out[0][0]',
'conv4_block6_3_bn[0][0]']
conv4_block6_out (Activati (None, 14, 14, 1024) 0 ['conv4_block6_add[0][0]']
on)
conv5_block1_1_conv (Conv2 (None, 7, 7, 512) 524800 ['conv4_block6_out[0][0]']
D)
conv5_block1_1_bn (BatchNo (None, 7, 7, 512) 2048 ['conv5_block1_1_conv[0][0]']
rmalization)
conv5_block1_1_relu (Activ (None, 7, 7, 512) 0 ['conv5_block1_1_bn[0][0]']
ation)
conv5_block1_2_conv (Conv2 (None, 7, 7, 512) 2359808 ['conv5_block1_1_relu[0][0]']
D)
conv5_block1_2_bn (BatchNo (None, 7, 7, 512) 2048 ['conv5_block1_2_conv[0][0]']
rmalization)
conv5_block1_2_relu (Activ (None, 7, 7, 512) 0 ['conv5_block1_2_bn[0][0]']
ation)
conv5_block1_0_conv (Conv2 (None, 7, 7, 2048) 2099200 ['conv4_block6_out[0][0]']
D)
conv5_block1_3_conv (Conv2 (None, 7, 7, 2048) 1050624 ['conv5_block1_2_relu[0][0]']
D)
conv5_block1_0_bn (BatchNo (None, 7, 7, 2048) 8192 ['conv5_block1_0_conv[0][0]']
rmalization)
conv5_block1_3_bn (BatchNo (None, 7, 7, 2048) 8192 ['conv5_block1_3_conv[0][0]']
rmalization)
conv5_block1_add (Add) (None, 7, 7, 2048) 0 ['conv5_block1_0_bn[0][0]',
'conv5_block1_3_bn[0][0]']
conv5_block1_out (Activati (None, 7, 7, 2048) 0 ['conv5_block1_add[0][0]']
on)
conv5_block2_1_conv (Conv2 (None, 7, 7, 512) 1049088 ['conv5_block1_out[0][0]']
D)
conv5_block2_1_bn (BatchNo (None, 7, 7, 512) 2048 ['conv5_block2_1_conv[0][0]']
rmalization)
conv5_block2_1_relu (Activ (None, 7, 7, 512) 0 ['conv5_block2_1_bn[0][0]']
ation)
conv5_block2_2_conv (Conv2 (None, 7, 7, 512) 2359808 ['conv5_block2_1_relu[0][0]']
D)
conv5_block2_2_bn (BatchNo (None, 7, 7, 512) 2048 ['conv5_block2_2_conv[0][0]']
rmalization)
conv5_block2_2_relu (Activ (None, 7, 7, 512) 0 ['conv5_block2_2_bn[0][0]']
ation)
conv5_block2_3_conv (Conv2 (None, 7, 7, 2048) 1050624 ['conv5_block2_2_relu[0][0]']
D)
conv5_block2_3_bn (BatchNo (None, 7, 7, 2048) 8192 ['conv5_block2_3_conv[0][0]']
rmalization)
conv5_block2_add (Add) (None, 7, 7, 2048) 0 ['conv5_block1_out[0][0]',
'conv5_block2_3_bn[0][0]']
conv5_block2_out (Activati (None, 7, 7, 2048) 0 ['conv5_block2_add[0][0]']
on)
conv5_block3_1_conv (Conv2 (None, 7, 7, 512) 1049088 ['conv5_block2_out[0][0]']
D)
conv5_block3_1_bn (BatchNo (None, 7, 7, 512) 2048 ['conv5_block3_1_conv[0][0]']
rmalization)
conv5_block3_1_relu (Activ (None, 7, 7, 512) 0 ['conv5_block3_1_bn[0][0]']
ation)
conv5_block3_2_conv (Conv2 (None, 7, 7, 512) 2359808 ['conv5_block3_1_relu[0][0]']
D)
conv5_block3_2_bn (BatchNo (None, 7, 7, 512) 2048 ['conv5_block3_2_conv[0][0]']
rmalization)
conv5_block3_2_relu (Activ (None, 7, 7, 512) 0 ['conv5_block3_2_bn[0][0]']
ation)
conv5_block3_3_conv (Conv2 (None, 7, 7, 2048) 1050624 ['conv5_block3_2_relu[0][0]']
D)
conv5_block3_3_bn (BatchNo (None, 7, 7, 2048) 8192 ['conv5_block3_3_conv[0][0]']
rmalization)
conv5_block3_add (Add) (None, 7, 7, 2048) 0 ['conv5_block2_out[0][0]',
'conv5_block3_3_bn[0][0]']
conv5_block3_out (Activati (None, 7, 7, 2048) 0 ['conv5_block3_add[0][0]']
on)
==================================================================================================
Total params: 23587712 (89.98 MB)
Trainable params: 23534592 (89.78 MB)
Non-trainable params: 53120 (207.50 KB)
__________________________________________________________________________________________________
Freeze the layers
for layer in base_model.layers[:33]:
layer.trainable = False
Custom Model
model = Sequential([
base_model,
Conv2D(32, (3, 3), activation='relu'),
GlobalAveragePooling2D(),
Flatten(),
Dense(128, activation='relu'),
Dropout(0.4),
Dense(256, activation='relu'),
Dropout(0.4),
Dense(CLASSES, activation='softmax')
])
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
resnet50 (Functional) (None, 7, 7, 2048) 23587712
conv2d (Conv2D) (None, 5, 5, 32) 589856
global_average_pooling2d ( (None, 32) 0
GlobalAveragePooling2D)
flatten (Flatten) (None, 32) 0
dense (Dense) (None, 128) 4224
dropout (Dropout) (None, 128) 0
dense_1 (Dense) (None, 256) 33024
dropout_1 (Dropout) (None, 256) 0
dense_2 (Dense) (None, 4) 1028
=================================================================
Total params: 24215844 (92.38 MB)
Trainable params: 23953188 (91.37 MB)
Non-trainable params: 262656 (1.00 MB)
_________________________________________________________________
Compile Model
model.compile(
optimizer=Adam(learning_rate=0.001),
loss='categorical_crossentropy',
metrics=['accuracy']
)
Set Callbacks
callbacks = [
ModelCheckpoint(filepath='model/resnet50/resnet50.keras', monitor='val_loss', save_best_only=True, verbose=1, mode='auto'),
ReduceLROnPlateau(monitor='val_loss', factor=0.1, patience=3, verbose=1),
EarlyStopping(monitor='val_loss', verbose=1, patience=5),
tensorboard
]
Start Tensorboard
%load_ext tensorboard
%tensorboard --logdir=log/resnet50/
Fit the Model
history = model.fit(X_train,
Y_train,
batch_size=BATCH_SIZE,
epochs=EPOCH,
validation_data=(X_test, Y_test),
callbacks=callbacks
)
Epoch 1/20
2024-12-14 18:45:06.362479: I external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:454] Loaded cuDNN version 8904
2024-12-14 18:45:10.831202: I external/local_xla/xla/service/service.cc:168] XLA service 0x7fdea9cdf610 initialized for platform CUDA (this does not guarantee that XLA will be used). Devices:
2024-12-14 18:45:10.831235: I external/local_xla/xla/service/service.cc:176] StreamExecutor device (0): NVIDIA GeForce RTX 3050 Laptop GPU, Compute Capability 8.6
2024-12-14 18:45:10.845818: I tensorflow/compiler/mlir/tensorflow/utils/dump_mlir_util.cc:269] disabling MLIR crash reproducer, set env var `MLIR_CRASH_REPRODUCER_DIRECTORY` to enable.
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
I0000 00:00:1734191110.939775 426987 device_compiler.h:186] Compiled cluster using XLA! This line is logged at most once for the lifetime of the process.
653/653 [==============================] - ETA: 0s - loss: 1.2957 - accuracy: 0.3818
Epoch 1: val_loss improved from inf to 1.86073, saving model to model/resnet50/resnet50.keras
653/653 [==============================] - 87s 92ms/step - loss: 1.2957 - accuracy: 0.3818 - val_loss: 1.8607 - val_accuracy: 0.3691 - lr: 0.0010
Epoch 2/20
651/653 [============================>.] - ETA: 0s - loss: 1.0962 - accuracy: 0.5169
Epoch 2: val_loss improved from 1.86073 to 1.20823, saving model to model/resnet50/resnet50.keras
653/653 [==============================] - 48s 73ms/step - loss: 1.0951 - accuracy: 0.5178 - val_loss: 1.2082 - val_accuracy: 0.4181 - lr: 0.0010
Epoch 3/20
653/653 [==============================] - ETA: 0s - loss: 0.9141 - accuracy: 0.6128
Epoch 3: val_loss improved from 1.20823 to 0.84988, saving model to model/resnet50/resnet50.keras
653/653 [==============================] - 50s 76ms/step - loss: 0.9141 - accuracy: 0.6128 - val_loss: 0.8499 - val_accuracy: 0.6371 - lr: 0.0010
Epoch 4/20
653/653 [==============================] - ETA: 0s - loss: 0.7563 - accuracy: 0.7009
Epoch 4: val_loss did not improve from 0.84988
653/653 [==============================] - 47s 72ms/step - loss: 0.7563 - accuracy: 0.7009 - val_loss: 0.8919 - val_accuracy: 0.6432 - lr: 0.0010
Epoch 5/20
653/653 [==============================] - ETA: 0s - loss: 0.6614 - accuracy: 0.7434
Epoch 5: val_loss improved from 0.84988 to 0.62626, saving model to model/resnet50/resnet50.keras
653/653 [==============================] - 49s 75ms/step - loss: 0.6614 - accuracy: 0.7434 - val_loss: 0.6263 - val_accuracy: 0.7381 - lr: 0.0010
Epoch 6/20
653/653 [==============================] - ETA: 0s - loss: 0.5779 - accuracy: 0.7756
Epoch 6: val_loss did not improve from 0.62626
653/653 [==============================] - 47s 72ms/step - loss: 0.5779 - accuracy: 0.7756 - val_loss: 0.6481 - val_accuracy: 0.7519 - lr: 0.0010
Epoch 7/20
653/653 [==============================] - ETA: 0s - loss: 0.5336 - accuracy: 0.8054
Epoch 7: val_loss did not improve from 0.62626
653/653 [==============================] - 48s 74ms/step - loss: 0.5336 - accuracy: 0.8054 - val_loss: 0.6483 - val_accuracy: 0.7657 - lr: 0.0010
Epoch 8/20
653/653 [==============================] - ETA: 0s - loss: 0.4573 - accuracy: 0.8277
Epoch 8: val_loss did not improve from 0.62626
Epoch 8: ReduceLROnPlateau reducing learning rate to 0.00010000000474974513.
653/653 [==============================] - 49s 76ms/step - loss: 0.4573 - accuracy: 0.8277 - val_loss: 0.8256 - val_accuracy: 0.7412 - lr: 0.0010
Epoch 9/20
653/653 [==============================] - ETA: 0s - loss: 0.3162 - accuracy: 0.8893
Epoch 9: val_loss improved from 0.62626 to 0.44506, saving model to model/resnet50/resnet50.keras
653/653 [==============================] - 49s 74ms/step - loss: 0.3162 - accuracy: 0.8893 - val_loss: 0.4451 - val_accuracy: 0.8346 - lr: 1.0000e-04
Epoch 10/20
653/653 [==============================] - ETA: 0s - loss: 0.2407 - accuracy: 0.9180
Epoch 10: val_loss improved from 0.44506 to 0.43980, saving model to model/resnet50/resnet50.keras
653/653 [==============================] - 50s 77ms/step - loss: 0.2407 - accuracy: 0.9180 - val_loss: 0.4398 - val_accuracy: 0.8453 - lr: 1.0000e-04
Epoch 11/20
653/653 [==============================] - ETA: 0s - loss: 0.1878 - accuracy: 0.9341
Epoch 11: val_loss did not improve from 0.43980
653/653 [==============================] - 47s 71ms/step - loss: 0.1878 - accuracy: 0.9341 - val_loss: 0.4438 - val_accuracy: 0.8515 - lr: 1.0000e-04
Epoch 12/20
653/653 [==============================] - ETA: 0s - loss: 0.1630 - accuracy: 0.9433
Epoch 12: val_loss did not improve from 0.43980
653/653 [==============================] - 48s 73ms/step - loss: 0.1630 - accuracy: 0.9433 - val_loss: 0.4579 - val_accuracy: 0.8530 - lr: 1.0000e-04
Epoch 13/20
653/653 [==============================] - ETA: 0s - loss: 0.1275 - accuracy: 0.9567
Epoch 13: val_loss did not improve from 0.43980
Epoch 13: ReduceLROnPlateau reducing learning rate to 1.0000000474974514e-05.
653/653 [==============================] - 46s 71ms/step - loss: 0.1275 - accuracy: 0.9567 - val_loss: 0.4924 - val_accuracy: 0.8484 - lr: 1.0000e-04
Epoch 14/20
653/653 [==============================] - ETA: 0s - loss: 0.1088 - accuracy: 0.9602
Epoch 14: val_loss did not improve from 0.43980
653/653 [==============================] - 48s 74ms/step - loss: 0.1088 - accuracy: 0.9602 - val_loss: 0.4802 - val_accuracy: 0.8499 - lr: 1.0000e-05
Epoch 15/20
653/653 [==============================] - ETA: 0s - loss: 0.0961 - accuracy: 0.9674
Epoch 15: val_loss did not improve from 0.43980
653/653 [==============================] - 47s 71ms/step - loss: 0.0961 - accuracy: 0.9674 - val_loss: 0.4828 - val_accuracy: 0.8545 - lr: 1.0000e-05
Epoch 15: early stopping
Evaluate the model
Classification Report
Y_pred = model.predict(X_test)
y_pred = np.argmax(Y_pred, axis=1)
Y_test = np.argmax(Y_test, axis=1)
print(classification_report(Y_test, y_pred, target_names=labels))
print('Test Accuracy:', accuracy_score(Y_test, y_pred))
21/21 [==============================] - 9s 217ms/step
precision recall f1-score support
glioma_tumor 0.89 0.83 0.86 219
meningioma_tumor 0.76 0.80 0.78 187
no_tumor 0.85 0.89 0.87 87
pituitary_tumor 0.94 0.93 0.93 160
accuracy 0.85 653
macro avg 0.86 0.86 0.86 653
weighted avg 0.86 0.85 0.86 653
Test Accuracy: 0.8545176110260337
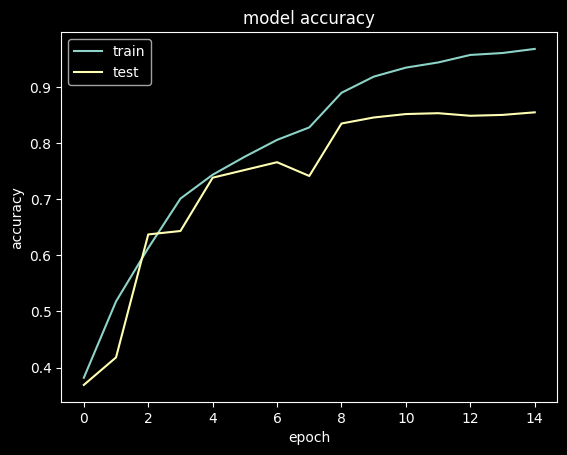
visualize training history
Accuracy
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
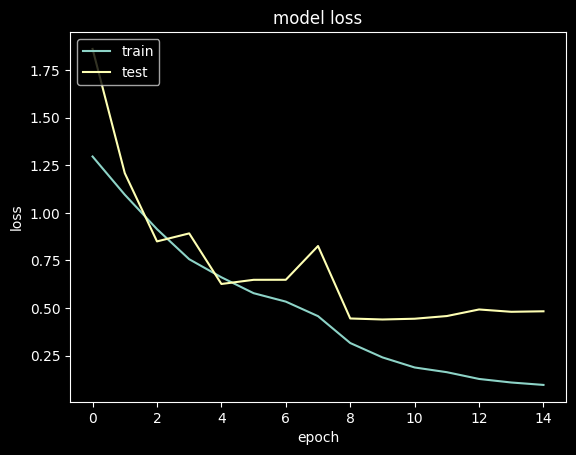
Loss
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
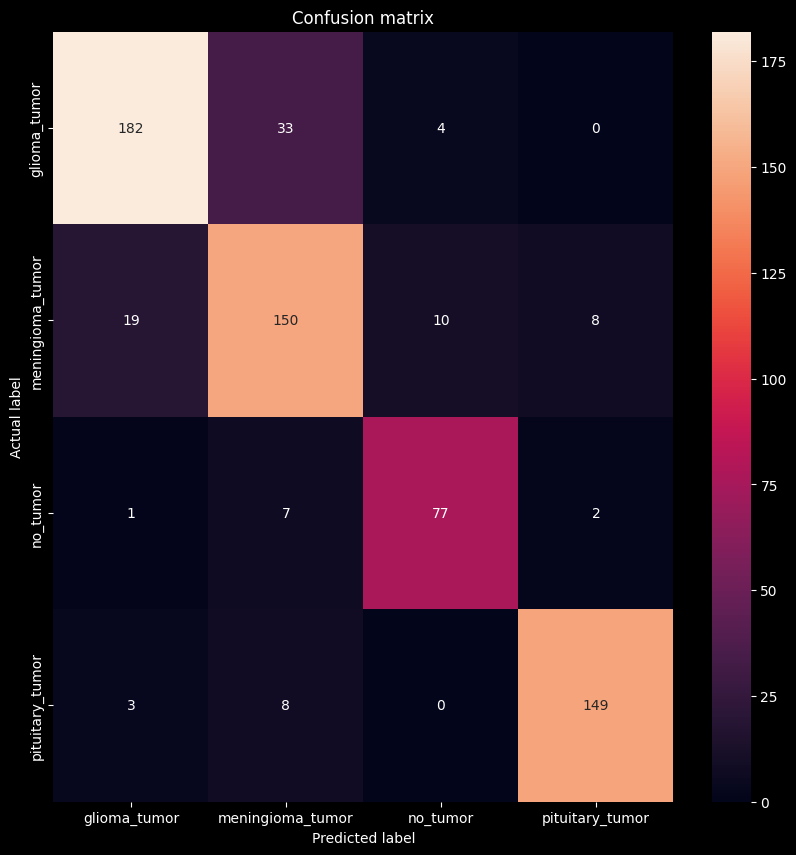
Confusion Matrix
cm = confusion_matrix(Y_test, y_pred)
plt.figure(figsize=(10, 10))
sns.heatmap(cm, annot=True, fmt="d", xticklabels=labels, yticklabels=labels)
plt.title('Confusion matrix')
plt.ylabel('Actual label')
plt.xlabel('Predicted label')
plt.show()
Save the Model
model.save('model/resnet50/resnet50.keras')
Load the Model
model = load_model('model/resnet50/resnet50.keras')
Predict
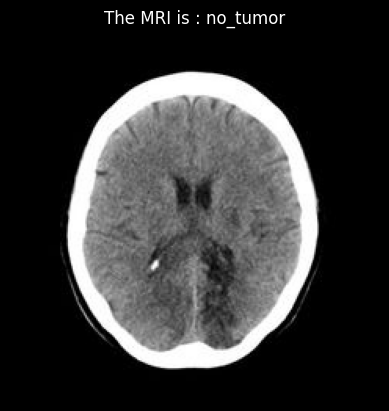
# Load the image file
image_path = 'dataset/Testing/no_tumor/image(16).jpg'
img = cv2.imread(image_path)
img = cv2.resize(img, (IMG_SIZE, IMG_SIZE))
img = np.reshape(img, [1, IMG_SIZE, IMG_SIZE, 3])
# Predict the image
prediction = model.predict(img)
prediction = labels[np.argmax(prediction)]
print('The MRI is : ', prediction)
# Display the image
plt.imshow(cv2.cvtColor(cv2.imread(image_path), cv2.COLOR_BGR2RGB))
plt.title('The MRI is : ' + prediction)
plt.axis('off')
plt.show()
1/1 [==============================] - 0s 31ms/step
The MRI is : no_tumor