K-NN (K-Nearest Neighbors)
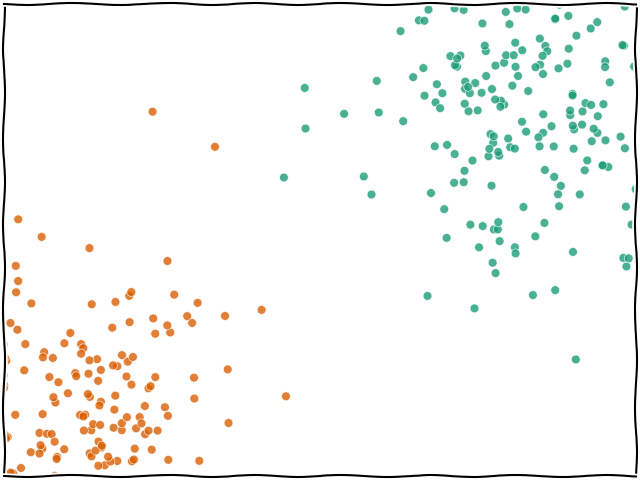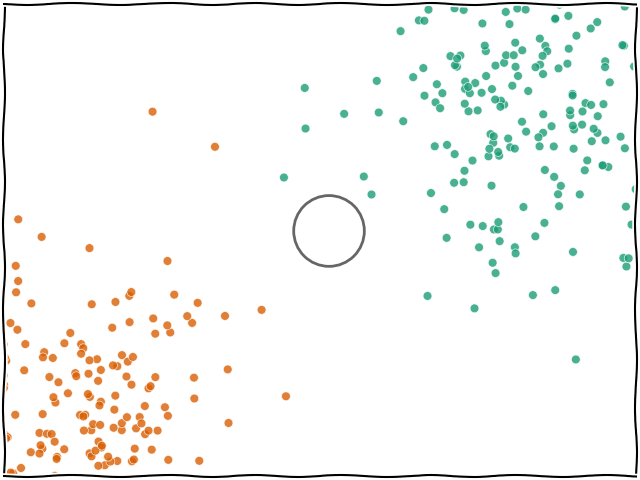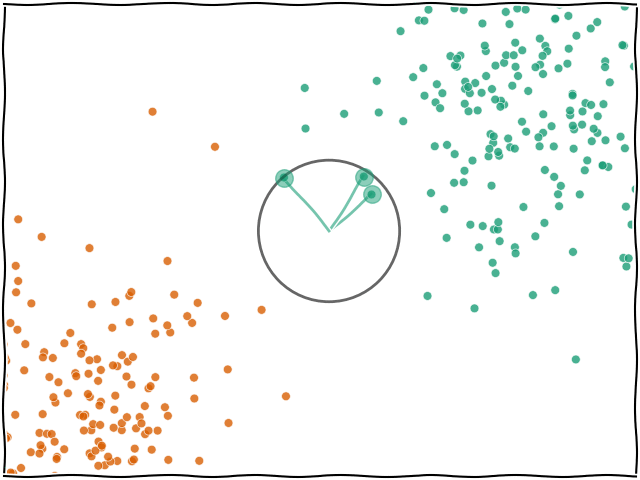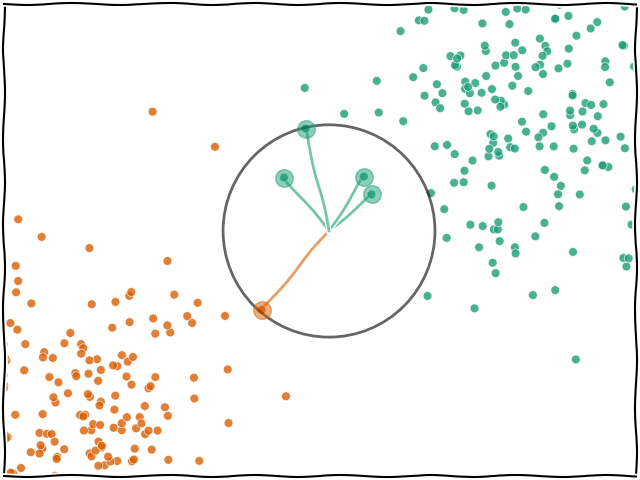
K-NN En Yakın Komşu (K-Nearest Neighbors) algoritması, gözetimli öğrenmeye dayalı ve temelde sınıflandırma veya regresyon problemlerinde kullanılan basit ve sezgisel bir algoritmadır. K-NN, bir veri noktasının sınıfını belirlemek için veri uzayındaki diğer noktalarla olan mesafelerini kullanır.
- 1. K-NN Algoritması Nasıl Çalışır?
- 2. K Değerinin Önemi
- 3. K-NN’nin Avantajları ve Dezavantajları
- 4. K-NN’nin Uygulama Alanları
- 5. Örnek Uygulama
- Dataset
- Import the necessary modules and libraries
- Description of Dataset
- Data Preprocessing
- Building Model
- Predict
- Evaluate
- Example Patient
K-NN, yeni bir veri noktasını sınıflandırmak için eğitim veri kümesindeki en yakın K komşuyu dikkate alır. Bir veri noktasına en yakın K komşunun sınıflarına bakarak yeni veri noktasının hangi sınıfa ait olduğu tahmin edilir. Algoritma, eğitim süreci sırasında bir model oluşturmaz, sadece mevcut veri noktalarını saklar ve tahmin yaparken bu noktalar arasındaki mesafeyi kullanır.
1. K-NN Algoritması Nasıl Çalışır?
K-NN, aşağıdaki adımları izleyerek çalışır:
a. Eğitim Verilerini Saklama:
K-NN bir “lazy learning” algoritmasıdır, yani eğitim aşamasında yalnızca verileri saklar ve herhangi bir genelleme yapmaz. Model eğitimi sırasında hesaplama yapmaz, tüm hesaplamalar tahmin aşamasında gerçekleştirilir.
b. Mesafe Hesaplama:
Bir yeni veri noktası geldiğinde, algoritma bu noktayı sınıflandırmak için eğitim veri kümesindeki tüm noktalarla olan mesafeyi hesaplar. Mesafe hesaplamada varsayılan olarak Minkowski mesafesi kullanılır, ancak bazı durumlarda Manhattan mesafesi, Euclidean mesafesi gibi başka mesafe ölçütleri de kullanılabilir.
Minkowski Distance: \[d(x, y) = \left( \sum_{i=1}^{n}{\left|x_i - y_i\right|^p}\right)^{\frac{1}{p}}\]
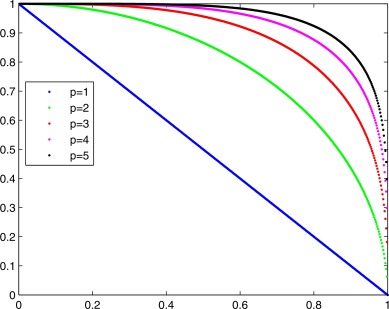
Euclidean Distance: \[d(p,q) = \sqrt{\sum_{i=1}^{n}{(p_i - q_i)^2}} = \sqrt{(p_1 - q_1)^2 + (p_2 - q_2)^2 + ... + (p_n - q_n)^2}\]

c. K En Yakın Komşuyu Bulma
Mesafeler hesaplandıktan sonra, yeni veri noktasına en yakın olan K adet veri noktası seçilir. Buradaki K, modelin bir hiperparametresidir ve seçilen en yakın komşuların sayısını ifade eder. K sayısı genellikle deneysel olarak belirlenir.
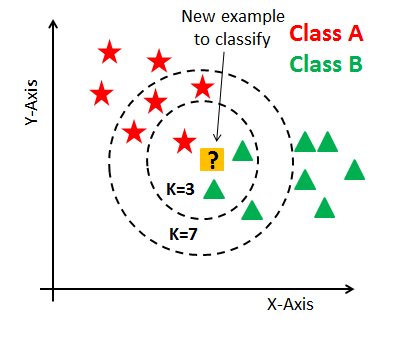
d. Sınıf Tahmini (Sınıflandırma) veya Değer Tahmini (Regresyon):
Sınıflandırma
K en yakın komşunun sınıflarına bakılır ve en çok tekrar eden sınıf, yeni veri noktasının sınıfı olarak atanır (çoğunluk oyu prensibi). Örneğin, en yakın komşular arasında 3 veri noktası varsa ve bunların ikisi sınıf A’ya ait, biri sınıf B’ye aitse, yeni nokta sınıf A olarak sınıflandırılır.
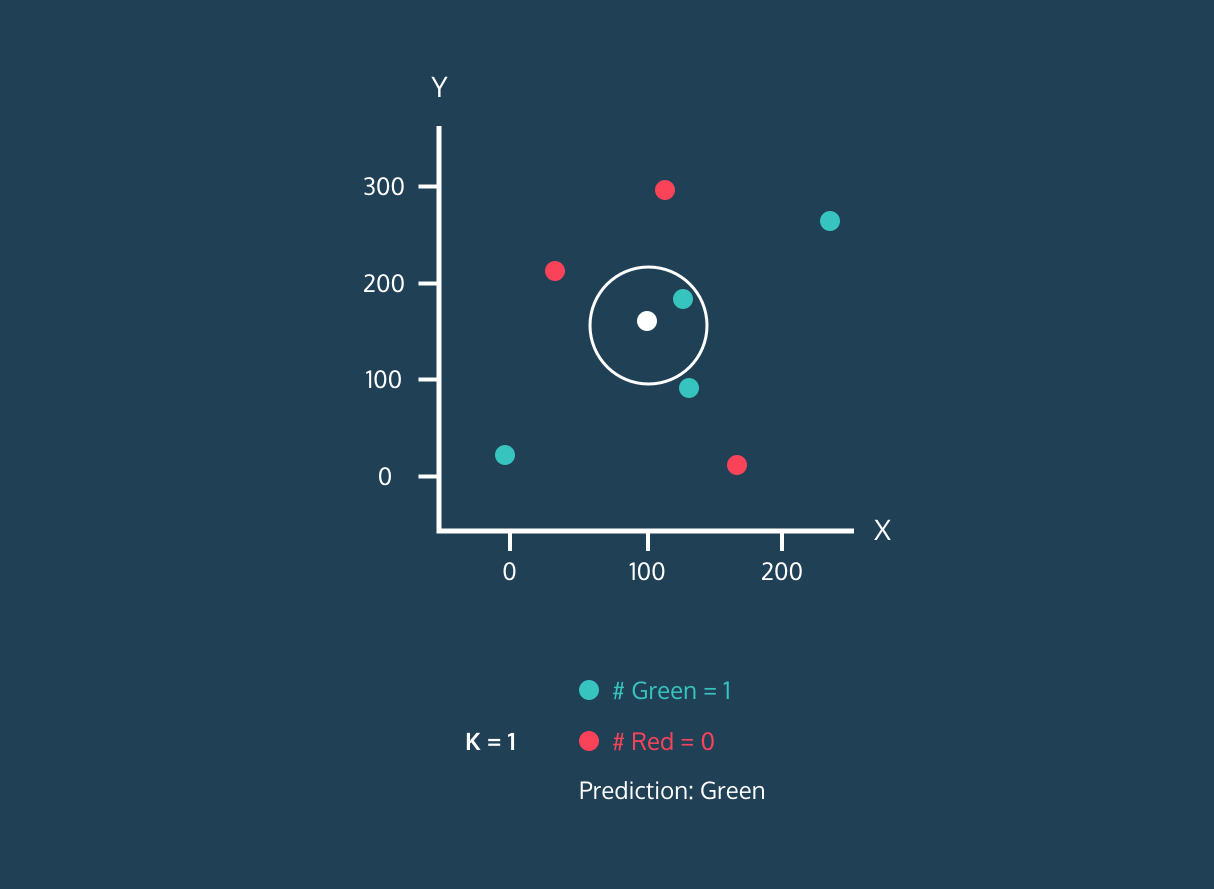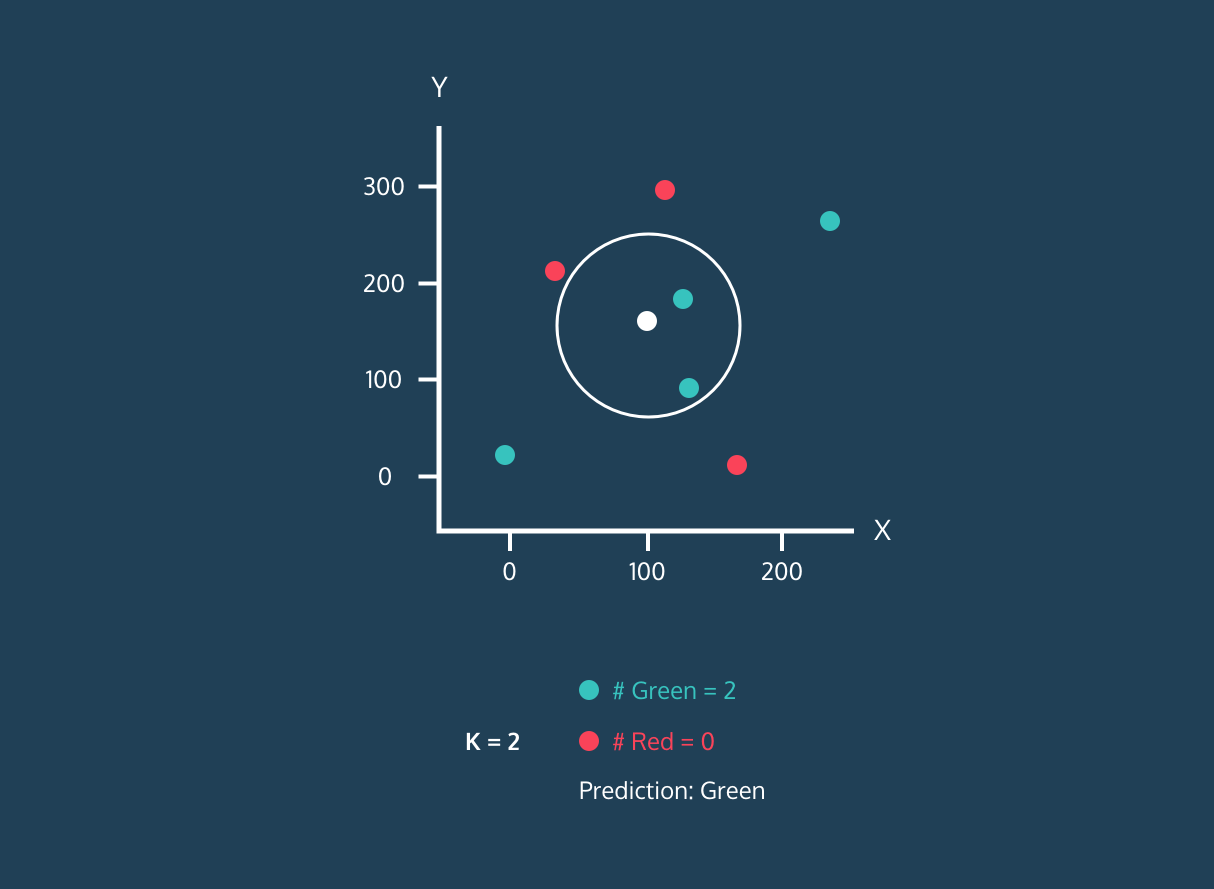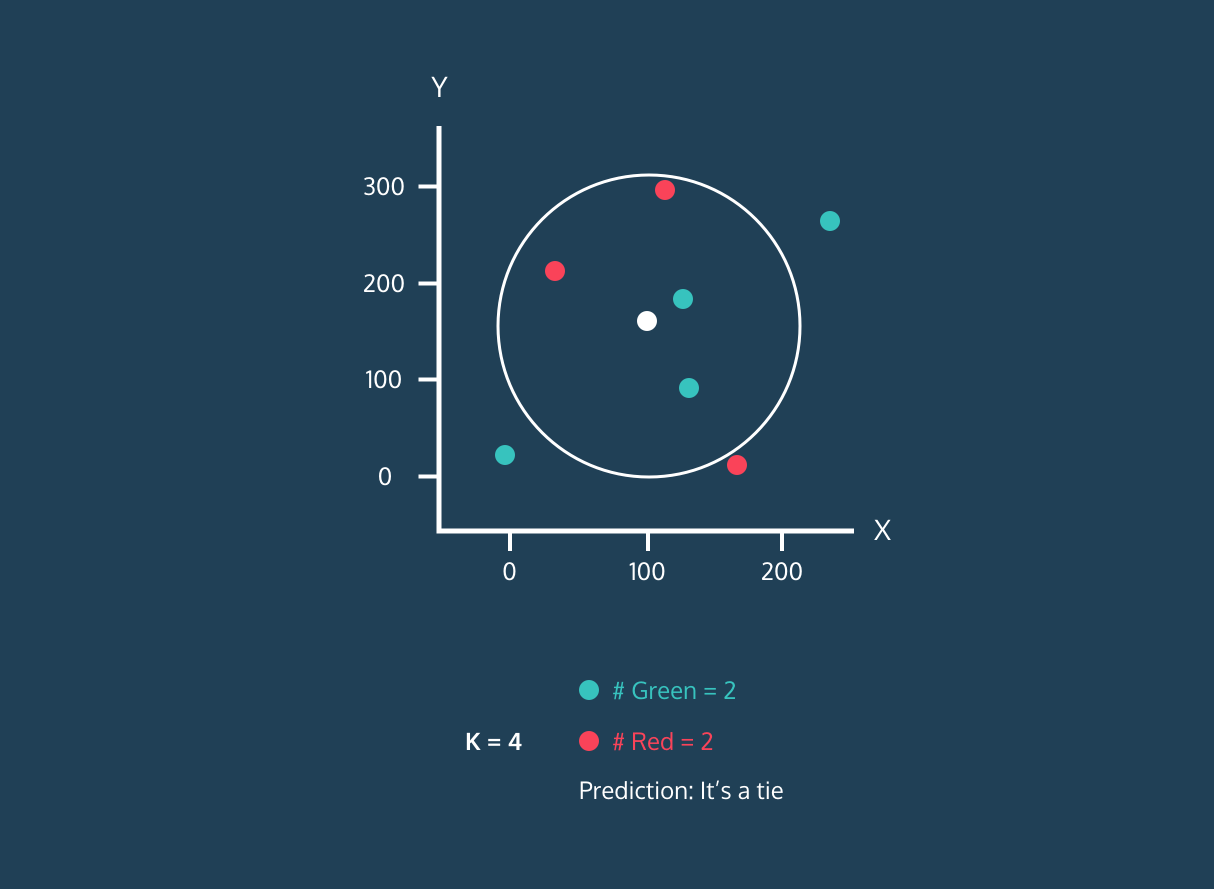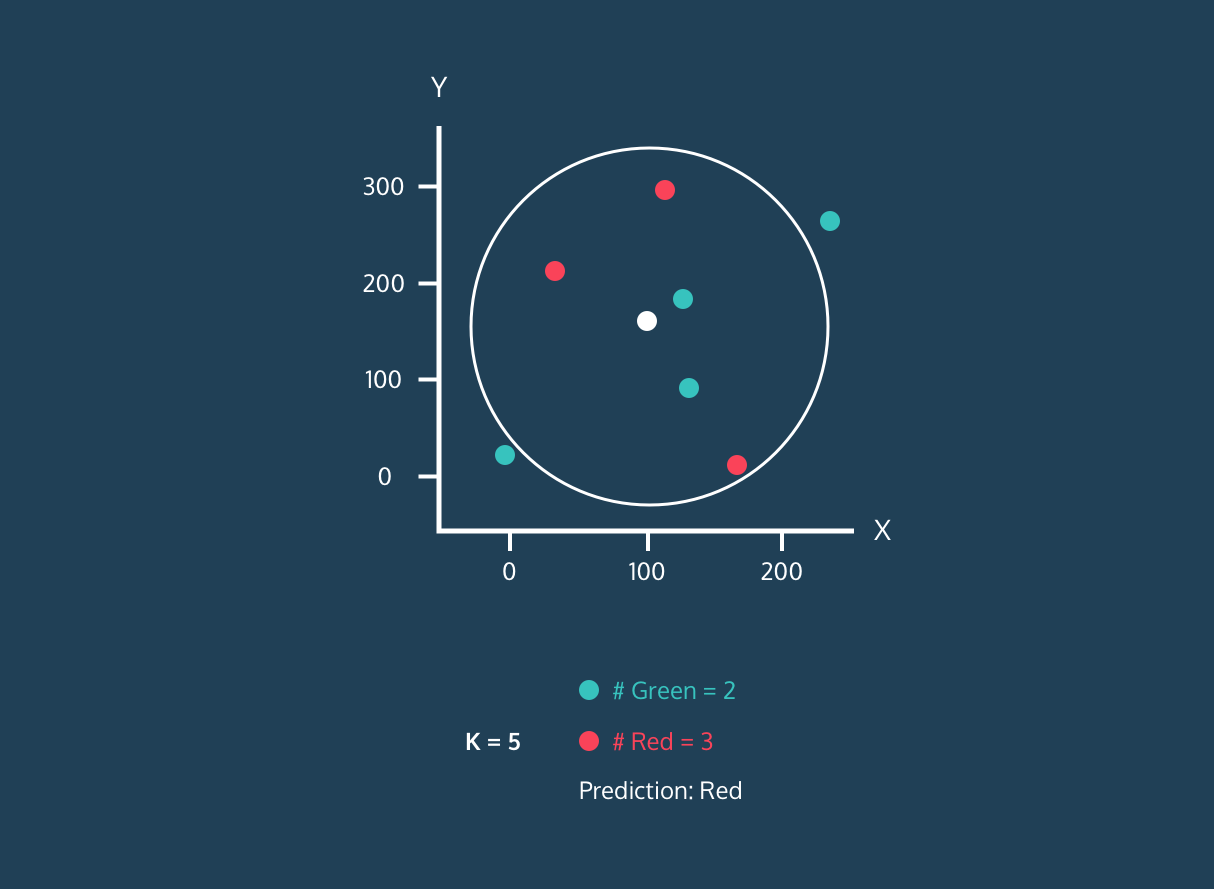
Regresyon
K en yakın komşunun değerlerinin ortalaması alınarak yeni veri noktasının değeri tahmin edilir.
2. K Değerinin Önemi
K değeri algoritmanın başarısını doğrudan etkiler:
- Eğer K değeri çok küçük seçilirse (örneğin K=1), model aşırı öğrenme (overfitting) yapabilir, yani eğitim verisine çok duyarlı hale gelir ve genelleme yeteneği zayıflar.
- Eğer K değeri çok büyük seçilirse, bu sefer modelin genelleme yeteneği artar ancak bazı detayları göz ardı edebilir, bu da modelin yetersiz öğrenmesine (underfitting) yol açabilir.
Genellikle K değeri olarak tek sayı tercih edilir ki, çoğunluk oyu prensibiyle karışıklık olmasın.
3. K-NN’nin Avantajları ve Dezavantajları
Avantajlar:
Basitlik
Algoritma oldukça basit ve sezgiseldir. Eğitimi oldukça hızlıdır çünkü sadece veri noktalarını saklar.
Parametrik Olmayan Yapı
K-NN, parametrik olmayan bir yöntemdir, yani veriyi herhangi bir dağılım varsayımına zorlamaz.
Eğitimsiz Model
K-NN modelinde herhangi bir eğitim aşaması olmadığından, dinamik verilerle kolayca kullanılabilir.
Dezavantajlar
Hafıza Tüketimi
K-NN, tüm eğitim verilerini sakladığı için hafıza açısından maliyetli olabilir.
Yavaşlık
K-NN, tahmin aşamasında her veri noktası için tüm mesafeleri hesapladığından büyük veri kümelerinde yavaş çalışabilir.
Kararsızlık (Ambiguity)
K en yakın komşular arasında eşit oy dağılımı varsa hangi sınıfın seçileceği konusunda kararsızlık oluşabilir.
Özniteliklerin Ölçeklendirilmesi
Veriler arasında büyük ölçek farkları varsa, mesafe hesaplamaları yanıltıcı olabilir. Bu nedenle özellik ölçeklendirme (normalizasyon veya standartlaştırma) çoğunlukla gereklidir.
4. K-NN’nin Uygulama Alanları
- Sınıflandırma Problemleri : E-posta spam sınıflandırma, el yazısı karakter tanıma, hastalık tespiti gibi.
- Regresyon Problemleri : Ev fiyat tahmini gibi.
- Öneri Sistemleri : Benzer kullanıcılar veya öğeler arasındaki yakınlıkları kullanarak önerilerde bulunmak.
K-NN, basitliği ve sezgiselliği ile küçük veri kümelerinde etkili bir sınıflandırma ve regresyon algoritmasıdır. Ancak büyük veri kümelerinde hesaplama maliyeti yüksek olabileceğinden, veri yapıları veya hızlandırma teknikleriyle birlikte kullanılabilir. Optimal K değeri deneysel olarak belirlenmelidir, bu sayede doğru denge sağlanabilir.
5. Örnek Uygulama
K-NN algoritmasını kullanarak meme kanserini tespit eden bir model oluşturalım.
Dataset
Import the necessary modules and libraries
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import confusion_matrix, classification_report, accuracy_score
import warnings
warnings.filterwarnings("ignore")
Description of Dataset
Read Data
df = pd.read_csv('breast_cancer_dataset.csv')
print(df.head(5))
id diagnosis radius_mean texture_mean perimeter_mean area_mean \
0 842302 M 17.99 10.38 122.80 1001.0
1 842517 M 20.57 17.77 132.90 1326.0
2 84300903 M 19.69 21.25 130.00 1203.0
3 84348301 M 11.42 20.38 77.58 386.1
4 84358402 M 20.29 14.34 135.10 1297.0
smoothness_mean compactness_mean concavity_mean concave points_mean \
0 0.11840 0.27760 0.3001 0.14710
1 0.08474 0.07864 0.0869 0.07017
2 0.10960 0.15990 0.1974 0.12790
3 0.14250 0.28390 0.2414 0.10520
4 0.10030 0.13280 0.1980 0.10430
... texture_worst perimeter_worst area_worst smoothness_worst \
0 ... 17.33 184.60 2019.0 0.1622
1 ... 23.41 158.80 1956.0 0.1238
2 ... 25.53 152.50 1709.0 0.1444
3 ... 26.50 98.87 567.7 0.2098
4 ... 16.67 152.20 1575.0 0.1374
compactness_worst concavity_worst concave points_worst symmetry_worst \
0 0.6656 0.7119 0.2654 0.4601
1 0.1866 0.2416 0.1860 0.2750
2 0.4245 0.4504 0.2430 0.3613
3 0.8663 0.6869 0.2575 0.6638
4 0.2050 0.4000 0.1625 0.2364
fractal_dimension_worst Unnamed: 32
0 0.11890 NaN
1 0.08902 NaN
2 0.08758 NaN
3 0.17300 NaN
4 0.07678 NaN
[5 rows x 33 columns]
print(df.describe())
id radius_mean texture_mean perimeter_mean area_mean \
count 5.690000e+02 569.000000 569.000000 569.000000 569.000000
mean 3.037183e+07 14.127292 19.289649 91.969033 654.889104
std 1.250206e+08 3.524049 4.301036 24.298981 351.914129
min 8.670000e+03 6.981000 9.710000 43.790000 143.500000
25% 8.692180e+05 11.700000 16.170000 75.170000 420.300000
50% 9.060240e+05 13.370000 18.840000 86.240000 551.100000
75% 8.813129e+06 15.780000 21.800000 104.100000 782.700000
max 9.113205e+08 28.110000 39.280000 188.500000 2501.000000
smoothness_mean compactness_mean concavity_mean concave points_mean \
count 569.000000 569.000000 569.000000 569.000000
mean 0.096360 0.104341 0.088799 0.048919
std 0.014064 0.052813 0.079720 0.038803
min 0.052630 0.019380 0.000000 0.000000
25% 0.086370 0.064920 0.029560 0.020310
50% 0.095870 0.092630 0.061540 0.033500
75% 0.105300 0.130400 0.130700 0.074000
max 0.163400 0.345400 0.426800 0.201200
symmetry_mean ... texture_worst perimeter_worst area_worst \
count 569.000000 ... 569.000000 569.000000 569.000000
mean 0.181162 ... 25.677223 107.261213 880.583128
std 0.027414 ... 6.146258 33.602542 569.356993
min 0.106000 ... 12.020000 50.410000 185.200000
25% 0.161900 ... 21.080000 84.110000 515.300000
50% 0.179200 ... 25.410000 97.660000 686.500000
75% 0.195700 ... 29.720000 125.400000 1084.000000
max 0.304000 ... 49.540000 251.200000 4254.000000
smoothness_worst compactness_worst concavity_worst \
count 569.000000 569.000000 569.000000
mean 0.132369 0.254265 0.272188
std 0.022832 0.157336 0.208624
min 0.071170 0.027290 0.000000
25% 0.116600 0.147200 0.114500
50% 0.131300 0.211900 0.226700
75% 0.146000 0.339100 0.382900
max 0.222600 1.058000 1.252000
concave points_worst symmetry_worst fractal_dimension_worst \
count 569.000000 569.000000 569.000000
mean 0.114606 0.290076 0.083946
std 0.065732 0.061867 0.018061
min 0.000000 0.156500 0.055040
25% 0.064930 0.250400 0.071460
50% 0.099930 0.282200 0.080040
75% 0.161400 0.317900 0.092080
max 0.291000 0.663800 0.207500
Unnamed: 32
count 0.0
mean NaN
std NaN
min NaN
25% NaN
50% NaN
75% NaN
max NaN
[8 rows x 32 columns]
print(df.info())
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 569 entries, 0 to 568
Data columns (total 33 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 569 non-null int64
1 diagnosis 569 non-null object
2 radius_mean 569 non-null float64
3 texture_mean 569 non-null float64
4 perimeter_mean 569 non-null float64
5 area_mean 569 non-null float64
6 smoothness_mean 569 non-null float64
7 compactness_mean 569 non-null float64
8 concavity_mean 569 non-null float64
9 concave points_mean 569 non-null float64
10 symmetry_mean 569 non-null float64
11 fractal_dimension_mean 569 non-null float64
12 radius_se 569 non-null float64
13 texture_se 569 non-null float64
14 perimeter_se 569 non-null float64
15 area_se 569 non-null float64
16 smoothness_se 569 non-null float64
17 compactness_se 569 non-null float64
18 concavity_se 569 non-null float64
19 concave points_se 569 non-null float64
20 symmetry_se 569 non-null float64
21 fractal_dimension_se 569 non-null float64
22 radius_worst 569 non-null float64
23 texture_worst 569 non-null float64
24 perimeter_worst 569 non-null float64
25 area_worst 569 non-null float64
26 smoothness_worst 569 non-null float64
27 compactness_worst 569 non-null float64
28 concavity_worst 569 non-null float64
29 concave points_worst 569 non-null float64
30 symmetry_worst 569 non-null float64
31 fractal_dimension_worst 569 non-null float64
32 Unnamed: 32 0 non-null float64
dtypes: float64(31), int64(1), object(1)
memory usage: 146.8+ KB
None
Data Preprocessing
Verisetinde diagnosis sütunu teşhisi belirtiyor:
- M - (malignant) : Kötü huylu (cancer)
- B - (benign) : İyi huylu (non-cancerous)
Bu M ve B değerlerini mapping işlemi ile sayısal değerlere dönüştürüyorum. (Kötü huylu 1 ve iyi huylu 0)
df['diagnosis'] = df['diagnosis'].map({'M': 1, 'B': 0})
print(df['diagnosis'].value_counts())
diagnosis
0 357
1 212
Name: count, dtype: int64
Checking and removing NAN values
Şimdi verisetinden NaN değerleri çıkartıyorum.
print(df.isnull().sum())
id 0
diagnosis 0
radius_mean 0
texture_mean 0
perimeter_mean 0
area_mean 0
smoothness_mean 0
compactness_mean 0
concavity_mean 0
concave points_mean 0
symmetry_mean 0
fractal_dimension_mean 0
radius_se 0
texture_se 0
perimeter_se 0
area_se 0
smoothness_se 0
compactness_se 0
concavity_se 0
concave points_se 0
symmetry_se 0
fractal_dimension_se 0
radius_worst 0
texture_worst 0
perimeter_worst 0
area_worst 0
smoothness_worst 0
compactness_worst 0
concavity_worst 0
concave points_worst 0
symmetry_worst 0
fractal_dimension_worst 0
Unnamed: 32 569
dtype: int64
Sadece hiç değer verilmeyen isimsiz bir sütun (Unnamed) var. O sütunu çıkartıyorum
df.dropna(axis=1, inplace=True)
print(df.isnull().sum())
id 0
diagnosis 0
radius_mean 0
texture_mean 0
perimeter_mean 0
area_mean 0
smoothness_mean 0
compactness_mean 0
concavity_mean 0
concave points_mean 0
symmetry_mean 0
fractal_dimension_mean 0
radius_se 0
texture_se 0
perimeter_se 0
area_se 0
smoothness_se 0
compactness_se 0
concavity_se 0
concave points_se 0
symmetry_se 0
fractal_dimension_se 0
radius_worst 0
texture_worst 0
perimeter_worst 0
area_worst 0
smoothness_worst 0
compactness_worst 0
concavity_worst 0
concave points_worst 0
symmetry_worst 0
fractal_dimension_worst 0
dtype: int64
id sütunu bir işe yaramayacağı için id sütununuda çıkartıyorum.
df.drop('id', axis=1, inplace=True)
print(df.columns)
Index(['diagnosis', 'radius_mean', 'texture_mean', 'perimeter_mean',
'area_mean', 'smoothness_mean', 'compactness_mean', 'concavity_mean',
'concave points_mean', 'symmetry_mean', 'fractal_dimension_mean',
'radius_se', 'texture_se', 'perimeter_se', 'area_se', 'smoothness_se',
'compactness_se', 'concavity_se', 'concave points_se', 'symmetry_se',
'fractal_dimension_se', 'radius_worst', 'texture_worst',
'perimeter_worst', 'area_worst', 'smoothness_worst',
'compactness_worst', 'concavity_worst', 'concave points_worst',
'symmetry_worst', 'fractal_dimension_worst'],
dtype='object')
Duplicated
df.duplicated().sum()
0
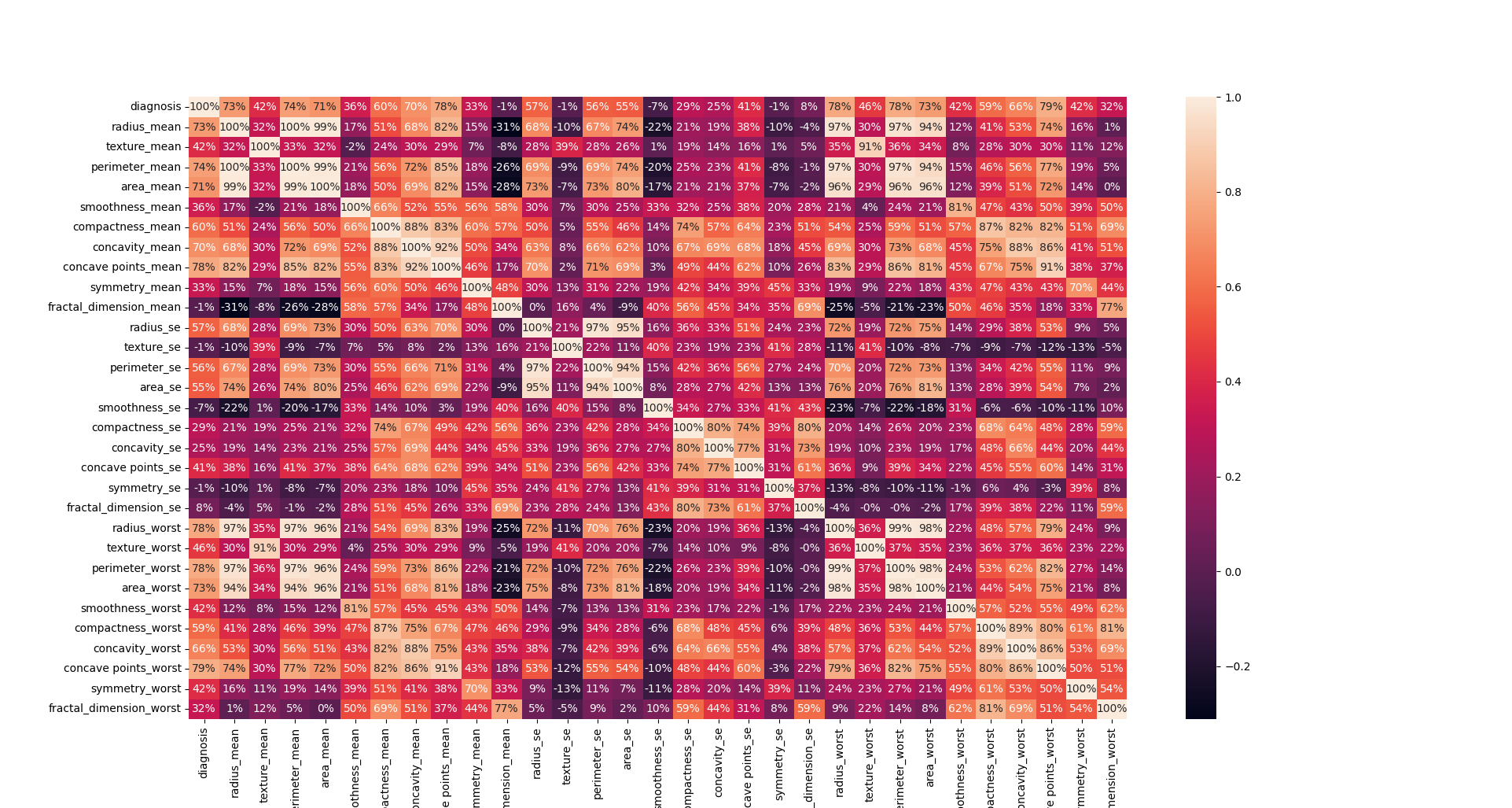
Graphical Analysis of Data
# graph shows that there are some features that are highly correlated with each other
plt.figure(figsize=(20, 20), dpi=100)
sns.heatmap(df.corr(), annot=True, fmt='.0%')
plt.show()
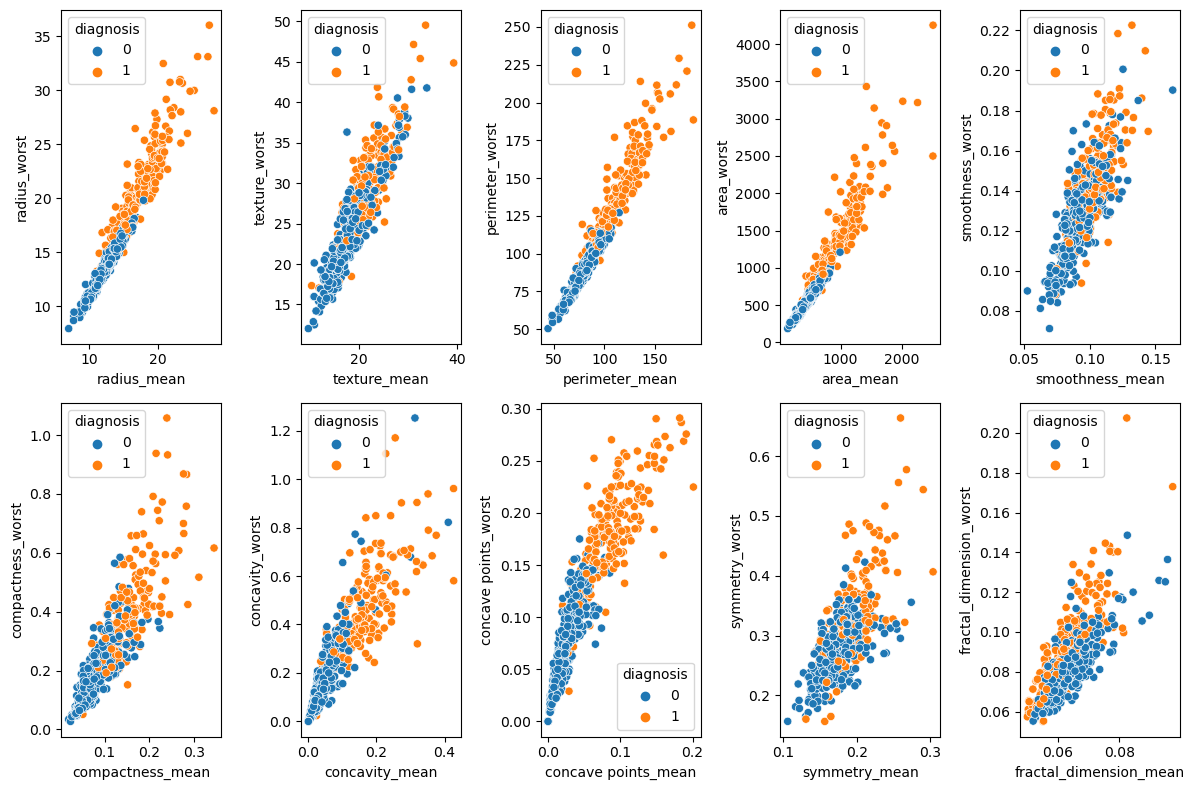
fig, axes = plt.subplots(nrows=2, ncols=5, figsize=(12, 8))
sns.scatterplot(data=df, x='radius_mean', y='radius_worst', hue='diagnosis', ax=axes[0, 0])
sns.scatterplot(data=df, x='texture_mean', y='texture_worst', hue='diagnosis', ax=axes[0, 1])
sns.scatterplot(data=df, x='perimeter_mean', y='perimeter_worst', hue='diagnosis', ax=axes[0, 2])
sns.scatterplot(data=df, x='area_mean', y='area_worst', hue='diagnosis', ax=axes[0, 3])
sns.scatterplot(data=df, x='smoothness_mean', y='smoothness_worst', hue='diagnosis', ax=axes[0, 4])
sns.scatterplot(data=df, x='compactness_mean', y='compactness_worst', hue='diagnosis', ax=axes[1, 0])
sns.scatterplot(data=df, x='concavity_mean', y='concavity_worst', hue='diagnosis', ax=axes[1, 1])
sns.scatterplot(data=df, x='concave points_mean', y='concave points_worst', hue='diagnosis', ax=axes[1,2])
sns.scatterplot(data=df, x='symmetry_mean', y='symmetry_worst', hue='diagnosis', ax=axes[1, 3])
sns.scatterplot(data=df, x='fractal_dimension_mean', y='fractal_dimension_worst', hue='diagnosis', ax=axes[1, 4])
plt.tight_layout()
plt.show()
Splitting Data
x = df.drop('diagnosis', axis=1)
y = df['diagnosis']
Train/Test Split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=0)
print(x_train.shape, x_test.shape)
(455, 30) (114, 30)
Scaling the Data
sc = StandardScaler()
x_train = sc.fit_transform(x_train)
x_test = sc.transform(x_test)
Building Model
Find the best k value
1’den 20’ye kadar olan bütün k değerlerini teker teker deneyerek en iyi k değerini bulmaya çalışalım.
def find_best_k(x_train, y_train):
"""
This function finds the best value of K for KNN algorithm
Parameters:
x_train: Training data
y_train: Training labels
Returns:
best_k: Best value of K for KNN algorithm
Example:
k = find_best_k(x_train, y_train)
"""
k_range = range(1, 20)
k_scores = []
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
scores = cross_val_score(knn, x_train, y_train, cv=10, scoring='accuracy')
k_scores.append(scores.mean())
plt.plot(k_range, k_scores)
plt.xlabel('Value of K for KNN')
plt.ylabel('Cross-Validated Accuracy')
plt.title('Value of K for KNN vs Cross-Validated Accuracy')
plt.show()
best_k = k_scores.index(max(k_scores)) + 1
print('Best K value is: ', best_k)
return best_k
k = find_best_k(x_train, y_train)
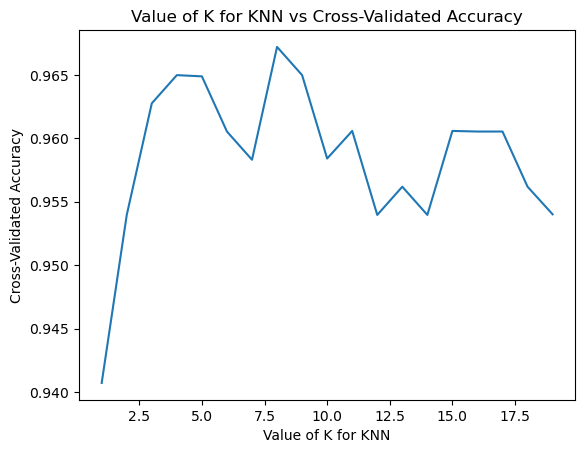
Best K value is: 8
Görüldüğü üzere en iyi k değerini 8 olarak belirledik. Şimdi k değerini 8 alarak K-NN modelini oluşturalım.
Create a KNN Model
knn = KNeighborsClassifier(n_neighbors=k, metric='minkowski')
Fit the Model
knn.fit(x_train, y_train)
KNeighborsClassifier(n_neighbors=8)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
KNeighborsClassifier(n_neighbors=8)
Predict
y_pred = knn.predict(x_test)
Evaluate
Accuracy of KNN
print('Accuracy of KNN: ', accuracy_score(y_test, y_pred))
Accuracy of KNN: 0.956140350877193
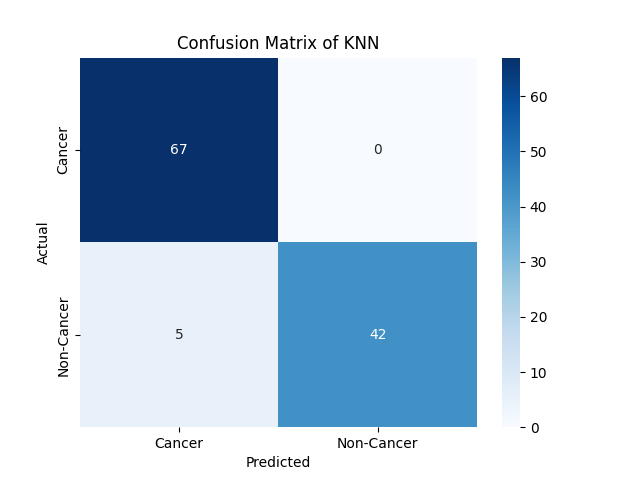
Confusion Matrix
cm = confusion_matrix(y_test, y_pred)
print(cm)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', xticklabels=['Cancer', 'Non-Cancer'], yticklabels=['Cancer', 'Non-Cancer'])
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.title('Confusion Matrix of KNN')
plt.show()
Classification Report
print(classification_report(y_test, y_pred))
precision recall f1-score support
0 0.93 1.00 0.96 67
1 1.00 0.89 0.94 47
accuracy 0.96 114
macro avg 0.97 0.95 0.95 114
weighted avg 0.96 0.96 0.96 114
Metriklerden de anlaşılacağı üzere 0.96 accuracy (kesinlik) değerine ve 0.95 f1 scoruna sahip kabul edilebilir ölçüde bir model oluşturduk.
Yani modelimiz oldukça başarılı bir şekilde kanserli ve kansersiz hücreleri ayırt edebiliyor.
Example Patient
example_patient = [[15.0, 20.0, 100.0, 700.0, 0.1, 0.2, 0.15, 0.08, 0.2,
0.05, 0.5, 1.0, 3.0,50.0, 0.01, 0.03, 0.02, 0.01, 0.02,
0.004, 18.0, 25.0, 120.0, 800.0, 0.14, 0.25, 0.2, 0.1, 0.3, 0.08]]
example_patient_pred = knn.predict(sc.transform(example_patient))
if example_patient_pred[0] == 0:
print('Example patient has benign tumor')
else:
print('Example patient has malignant tumor')
Example patient has malignant tumor
Örnek hastanın değerleri verildiğinde, modelimiz bu hastanın kanserli olduğunu tahmin etti.