Random Forest
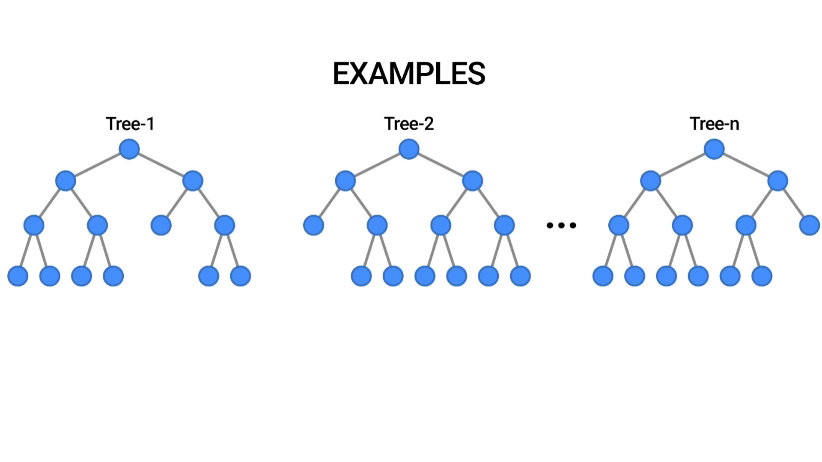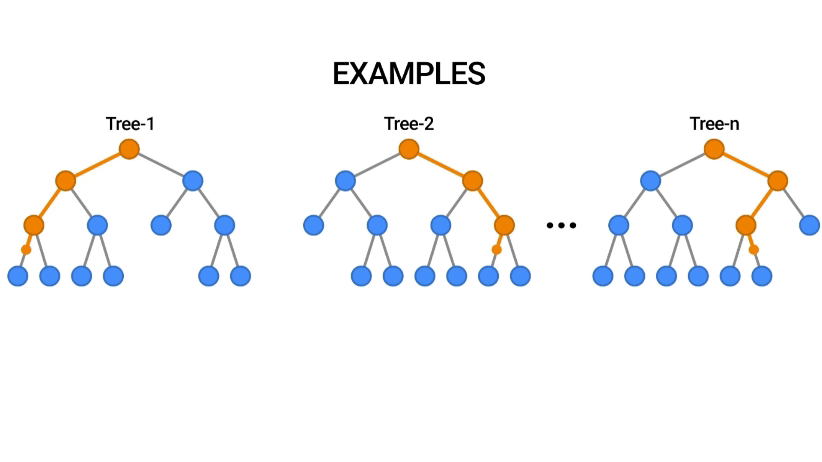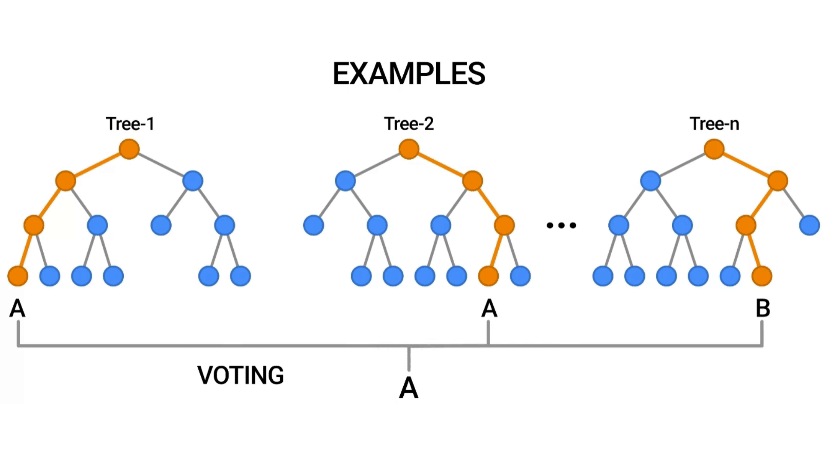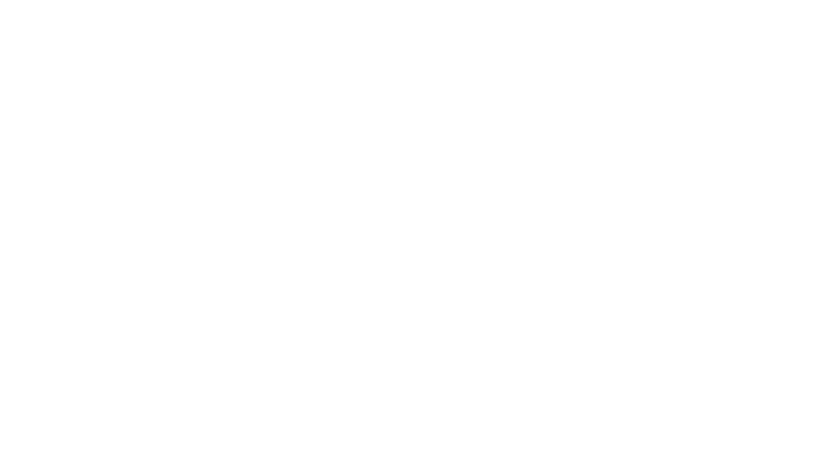
Random Forest, güçlü bir algoritma olup, genellikle yüksek doğruluk oranları sağlar ve birçok uygulamada tercih edilen bir yöntemdir.
- Nasıl Çalışır?
- Avantajları
- Dezavantajları
- Dataset
- Import the necessary modules and libraries
- Data Preprocessing
- Creating the Model
- Fit Regression Model
- Predict
- Visualize the Random Forest Regression results
- Evaluation of Model
Random Forest, makine öğrenmesinde kullanılan popüler bir ensemble (topluluk) öğrenme yöntemidir. Bu algoritma, birden fazla karar ağacı modelinin bir araya getirilmesiyle oluşturulur ve genellikle sınıflandırma ve regresyon problemlerinde kullanılır.
Nasıl Çalışır?
1. Karar Ağaçları
Random Forest, birden fazla karar ağacı oluşturur. Her bir karar ağacı, eğitim verilerinin rastgele bir alt kümesiyle ve özelliklerin rastgele bir alt kümesiyle eğitilir. Bu süreç, ağaçların birbirinden bağımsız olmasını ve farklı kararlar alabilmesini sağlar.
Karar ağaçları hakkında bilgi edinmek için Decision Trees konusunu okuyunuz.
2. Ensemble (Topluluk) Learning Yaklaşımı
Ensemble learning, makine öğrenmesinde birden fazla modelin bir araya getirilerek daha güçlü ve daha doğru bir model oluşturma yöntemidir. Bu yaklaşım, her bir modelin tek başına elde edebileceği performanstan daha iyi sonuçlar elde etmek amacıyla kullanılır.
Her bir karar ağacı, tahminini yapar. Sınıflandırma problemlerinde, her ağaç bir sınıf tahmini yapar ve en fazla oy alan sınıf, modelin nihai tahmini olur. Regresyon problemlerinde ise, ağaçların tahminlerinin ortalaması alınarak nihai sonuç elde edilir.
Temel Ensemble Learning Yaklaşımları
1. Bagging (Bootstrap Aggregating)
Bagging, eğitim verisinin rastgele alt kümeleri kullanılarak birden fazla model (genellikle aynı türde) eğitilmesi ve bu modellerin sonuçlarının birleştirilmesi işlemidir.
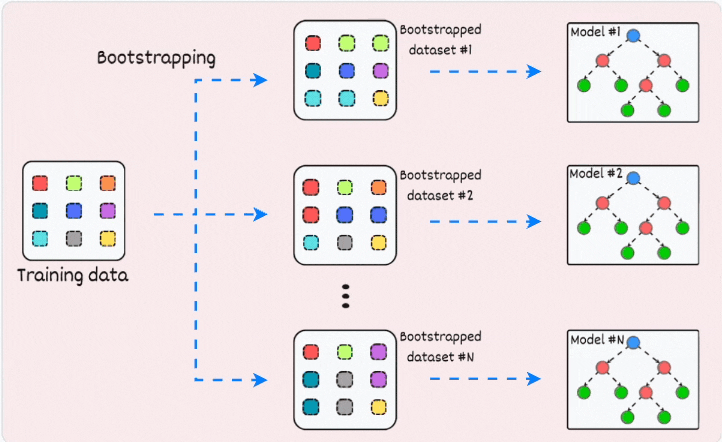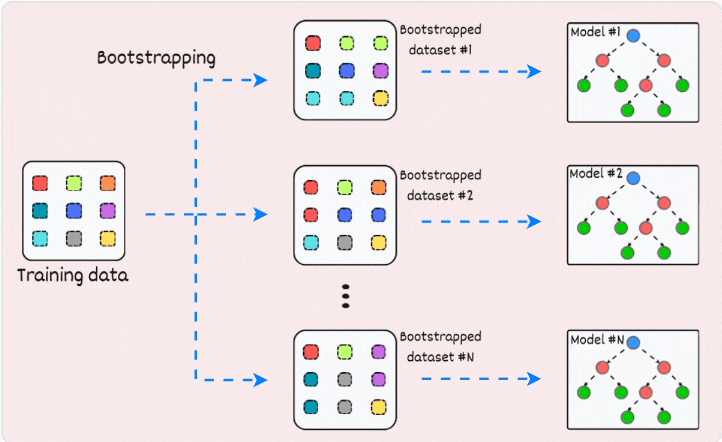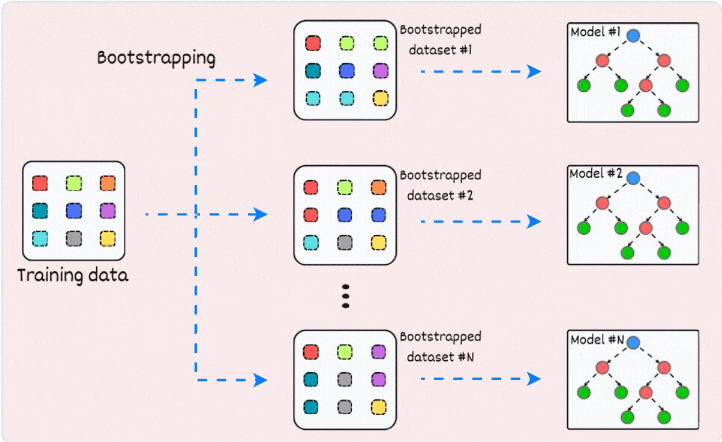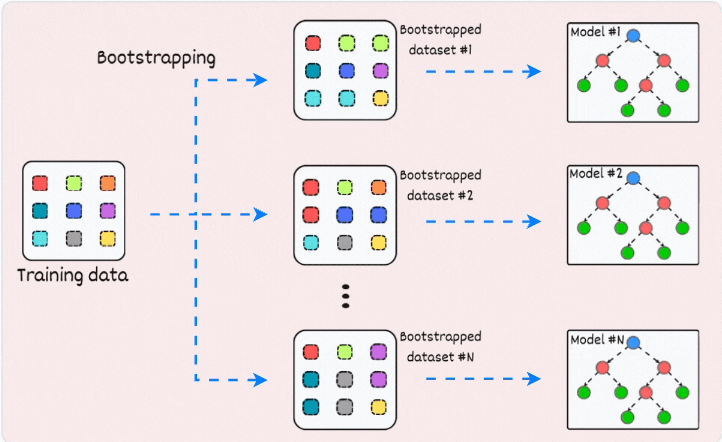
Bu yöntem, her bir modelin farklı veri alt kümeleri üzerinde eğitilmesini sağlar, bu da modelin genelleme yeteneğini artırır. Örneğin, Random Forest algoritması, karar ağaçlarının bagging yöntemini kullanarak bir araya getirilmesidir.
Avantajları: Bagging, modeli daha kararlı hale getirir ve varyansı azaltır.
2. Boosting
Boosting, zayıf modellerin (genellikle basit modellerin) ardışık olarak eğitilmesi ve her yeni modelin önceki modellerin hatalarını düzeltmeye çalışması prensibine dayanır.
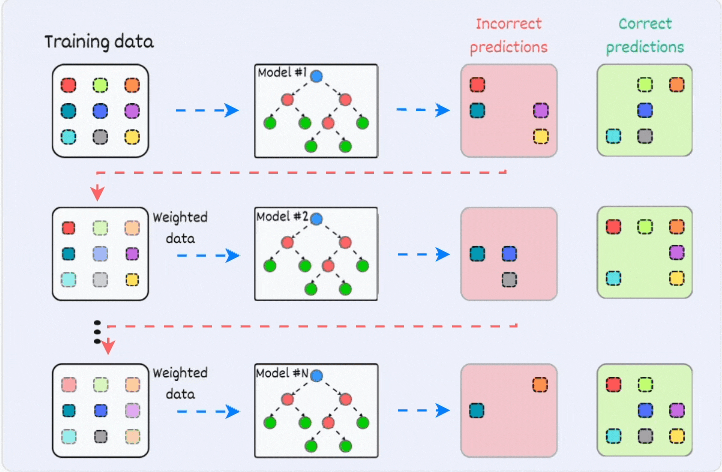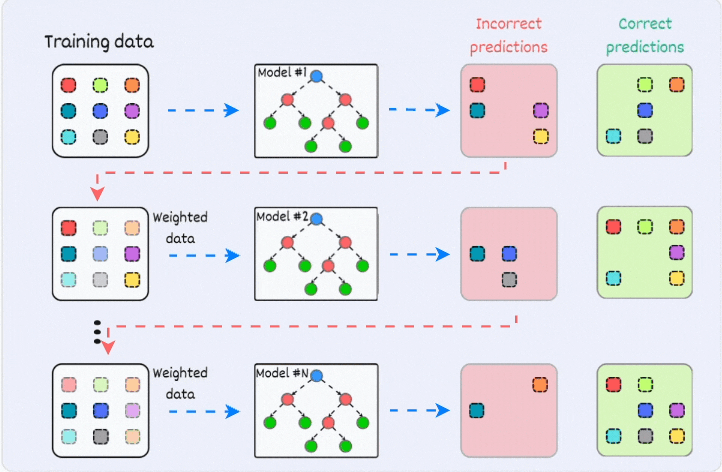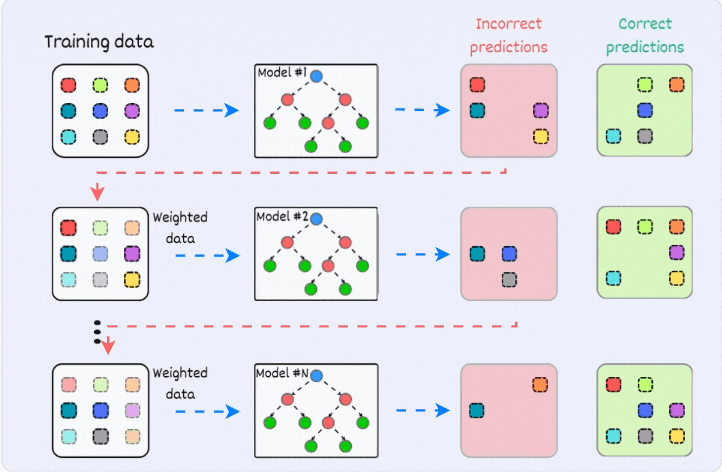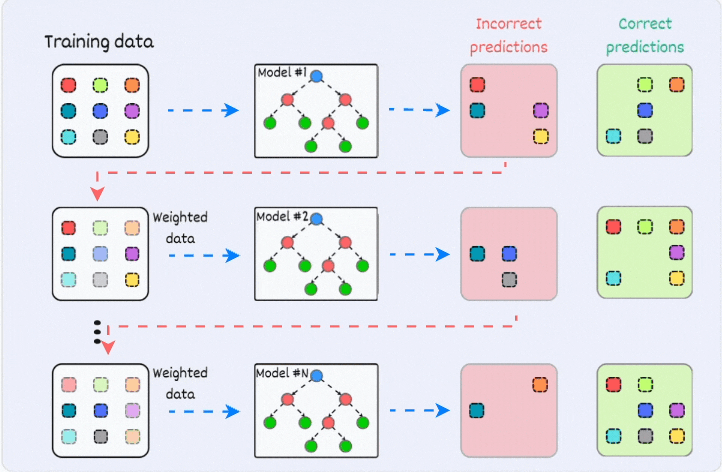
Her adımda, yanlış sınıflandırılmış örneklere daha fazla ağırlık verilir, böylece sonraki model bu örnekleri daha iyi öğrenmeye çalışır. Örneğin, AdaBoost ve Gradient Boosting, boosting yöntemine dayanan popüler algoritmalardır.
Avantajları: Boosting, genellikle çok yüksek doğruluk oranları sağlar ve özellikle zorlayıcı veri setlerinde etkilidir.
3. Stacking
Stacking, farklı türdeki modellerin çıktılarının bir araya getirilip, bu çıktılardan yeni bir model (meta-model) eğitilmesi yöntemidir.
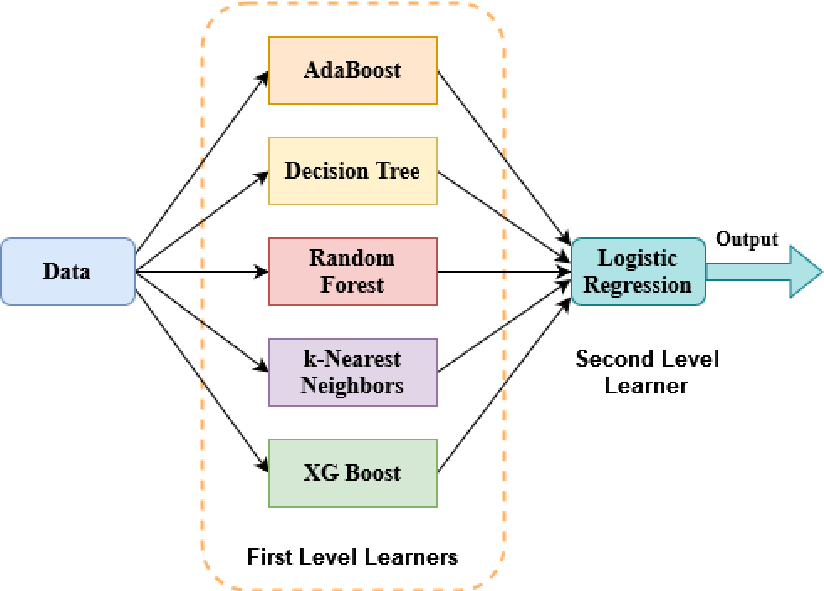
Stacking, çeşitli modellerin güçlü yönlerinden yararlanarak daha iyi performans elde etmeyi amaçlar. Bu yöntem, genellikle farklı türdeki modellerin kombinasyonunu içerir (örneğin, karar ağaçları, lojistik regresyon, SVM gibi).
Avantajları: Stacking, model çeşitliliği sayesinde esneklik sağlar ve genellikle daha yüksek bir doğruluk elde edilir.
3. Overfitting Azaltma
Karar ağaçları genellikle aşırı uyum (overfitting) yapma eğilimindedir. Ancak, birden fazla karar ağacının bir araya getirilmesi ve her ağacın farklı bir veri alt kümesiyle eğitilmesi, bu sorunu azaltır ve modelin genelleme yeteneğini artırır.
Avantajları
- Genelleme Yeteneği: Birden fazla karar ağacı kullanıldığı için model, veri setindeki gürültüden etkilenmez ve daha iyi genelleme yapar.
- Overfitting’e Dayanıklılık: Karar ağaçlarının bir araya getirilmesi, aşırı uyum riskini azaltır.
- Esneklik: Hem sınıflandırma hem de regresyon problemlerinde kullanılabilir.
Dezavantajları
- Hesaplama Maliyeti: Birden fazla karar ağacı oluşturulması gerektiğinden, özellikle büyük veri setlerinde eğitim süreci uzun sürebilir.
- Yorumlanabilirlik: Birden fazla ağacın bir araya getirilmesi, modelin karmaşıklığını artırır ve kararların yorumlanmasını zorlaştırır.
Şimdi salaries.csv verisetindeki eğitim seviyesi (X) bağımsız değişkeni ile, maaş (Y) bağımlı değişkenini tahmin eden bir Random Forest modeli oluşturalım.
Dataset
Import the necessary modules and libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sbn
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import r2_score
Data Preprocessing
Read Data
data = pd.read_csv('salaries.csv')
print(data.head(10))
unvan Egitim Seviyesi maas
0 Cayci 1 2250
1 Sekreter 2 2500
2 Uzman Yardimcisi 3 3000
3 Uzman 4 4000
4 Proje Yoneticisi 5 5500
5 Sef 6 7500
6 Mudur 7 10000
7 Direktor 8 15000
8 C-level 9 25000
9 CEO 10 50000
Graphical Analysis of Data
sbn.pairplot(data)
Split Data
egitim_seviyesi_X = data.iloc[:,1:2].values
maas_Y = data.iloc[:,2:].values
for i in range(len(egitim_seviyesi_X)):
print("Egitim Seviyesi: ",egitim_seviyesi_X[i],"Maas: ",maas_Y[i])
Egitim Seviyesi: [1] Maas: [2250]
Egitim Seviyesi: [2] Maas: [2500]
Egitim Seviyesi: [3] Maas: [3000]
Egitim Seviyesi: [4] Maas: [4000]
Egitim Seviyesi: [5] Maas: [5500]
Egitim Seviyesi: [6] Maas: [7500]
Egitim Seviyesi: [7] Maas: [10000]
Egitim Seviyesi: [8] Maas: [15000]
Egitim Seviyesi: [9] Maas: [25000]
Egitim Seviyesi: [10] Maas: [50000]
Creating the Model
Şimdi RandomForestRegressor sınıfını kullanarak bir random forest modeli oluşturalım. Bu sınıfı kullanırken aldığı parametreler modelin nasıl inşa edileceğini belirler.
rf_reg = RandomForestRegressor(n_estimators=10,
criterion='squared_error',
max_depth=None,
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.0,
max_features=1.0,
max_leaf_nodes=None,
min_impurity_decrease=0.0,
bootstrap=True,
oob_score=False,
n_jobs=None,
random_state=None,
verbose=0,
warm_start=False,
ccp_alpha=0.0,
max_samples=None, )
Parameters
Modeli oluştururken kullanılan parametrelerin aldığı değerler default değerlerdir. Bu parametrelerin bağzılarının açıklamaları şu şekildedir:
1. n_estimators=10 :
Random Forest modelindeki karar ağaçlarının sayısını belirtir. Bu örnekte, model 10 adet karar ağacından oluşacaktır. Daha fazla ağaç genellikle daha iyi performans sağlar, ancak işlem süresi de artar.
2. criterion='squared_error' :
Her bir karar ağacında dallanma kararlarını verirken kullanılan kriterdir. squared_error, varyansı en aza indirmeye çalışır ve regresyon problemleri için uygun bir kriterdir.
3. max_depth=None :
Karar ağaçlarının maksimum derinliğini belirler. None değeri, ağaçların maksimum derinliğe kadar büyümesine izin verir, bu da her bir yaprağın saf olana kadar (örneğin, her bir yaprakta tek bir örnek kalana kadar) büyüyeceği anlamına gelir.
4. min_samples_leaf=1 :
Her yaprakta (son düğümde) bulunması gereken minimum örnek sayısıdır. 1 değeri, yaprakta en az bir örnek bulunmasını sağlar.
5. max_leaf_nodes=None :
Karar ağaçlarındaki maksimum yaprak düğüm sayısını sınırlar. None, ağaçlarda sınırsız sayıda yaprak düğümü olabileceğini belirtir.
6. bootstrap=True :
Modeli eğitirken örneklerin rastgele seçilip seçilmeyeceğini belirtir. True olduğunda, her bir ağacın eğitim verileri, bootstrap (yeniden örnekleme) yöntemiyle seçilir.
7. oob_score=False :
Out-of-Bag (OOB) hatasını hesaplamak isteyip istemediğinizi belirler. True olarak ayarlandığında, OOB verileri üzerinde model performansını değerlendiren bir hata skoru hesaplanır. Bu, çapraz doğrulamaya benzer bir yöntemdir.
8. n_jobs=None :
Modelin eğitimi sırasında kullanılacak işlemci çekirdeği sayısını belirtir. None, varsayılan olarak tek bir çekirdek kullanır. -1 olarak ayarlanırsa, tüm mevcut çekirdekler kullanılır. Eğer büyük bir veri seti üzerinde çalışılıyorsa tüm çekirdekleri kullanmak daha hızlı bir model eğitimi sağlar.
9. random_state=None :
Rastgele sayı üreteci için başlangıç değeri (seed) sağlar. Bu, modelin çıktılarının tekrarlanabilir olmasını sağlar. None olarak bırakıldığında, rastgelelik kontrol edilmez.
10. warm_start=False :
True olarak ayarlandığında, modelin yeniden eğitilmesi sırasında önceki fit sonuçları kullanılır ve model üzerine ek ağaçlar eklenir. False, her eğitimde modelin sıfırdan başlaması anlamına gelir.
Bu parametreler, RandomForestRegressor modelinin esnekliğini ve performansını çeşitli şekillerde kontrol etmenizi sağlar. Modeli özelleştirerek veri setinize ve probleminize uygun hale getirebilirsiniz.
Fit Regression Model
rf_reg.fit(egitim_seviyesi_X, maas_Y)
RandomForestRegressor(n_estimators=10)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
RandomForestRegressor(n_estimators=10)
Predict
Şimdi oluşturmuş ve eğitmiş olduğumuz modelimizde tahminlerde bulunalım.
predict_1 = rf_reg.predict([[11]]) # Eğitim seviyesi 11 olan kişinin maaşının tahmini
predict_2 = rf_reg.predict([[6.6]]) # Eğitim seviyesi 6.6 olan kişinin maaşının tahmini
print("Eğitim Seviyesi 11 olan kişinin tahmini maaşı: ",predict_1)
print("Eğitim Seviyesi 6.6 olan kişinin tahmini maaşı: ",predict_2)
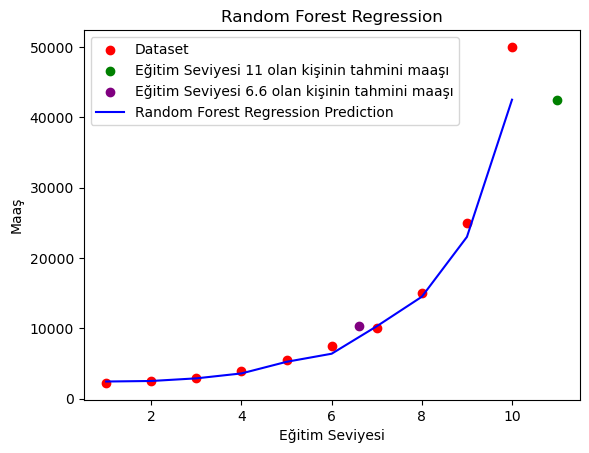
Eğitim Seviyesi 11 olan kişinin tahmini maaşı: [42500.]
Eğitim Seviyesi 6.6 olan kişinin tahmini maaşı: [10300.]
Eğer tek bir decision tree kullanılmış olsaydı sonuçlar farklı olacaktı. Çünkü decision tree tek bir ağaç üzerinden tahmin yapar ve bu ağaç üzerindeki verilere göre tahmin yapar. Ama random forest algoritması birden fazla decision tree üzerinden tahmin yapar ve bu ağaçların ortalamasını alarak tahmin yapar. Bu sayede daha doğru tahminler yapabilir.
Visualize the Random Forest Regression results
plt.scatter(egitim_seviyesi_X, maas_Y, color='red', label='Dataset')
plt.scatter(11, predict_1, color='green', label='Eğitim Seviyesi 11 olan kişinin tahmini maaşı')
plt.scatter(6.6, predict_2, color='purple', label='Eğitim Seviyesi 6.6 olan kişinin tahmini maaşı')
plt.plot(egitim_seviyesi_X, rf_reg.predict(egitim_seviyesi_X), color='blue', label='Random Forest Regression Prediction')
plt.title('Random Forest Regression')
plt.xlabel('Eğitim Seviyesi')
plt.ylabel('Maaş')
plt.legend()
plt.show()
Evaluation of Model
print("Random Forest R2 Değeri: ",r2_score(maas_Y, rf_reg.predict(egitim_seviyesi_X)))
Random Forest R2 Değeri: 0.969218252652263
Grafiktende anlaşılacağı üzere 0.969218252652263 -> 0.97 R2 değerine sahip bir başarı oranı elde ettik.