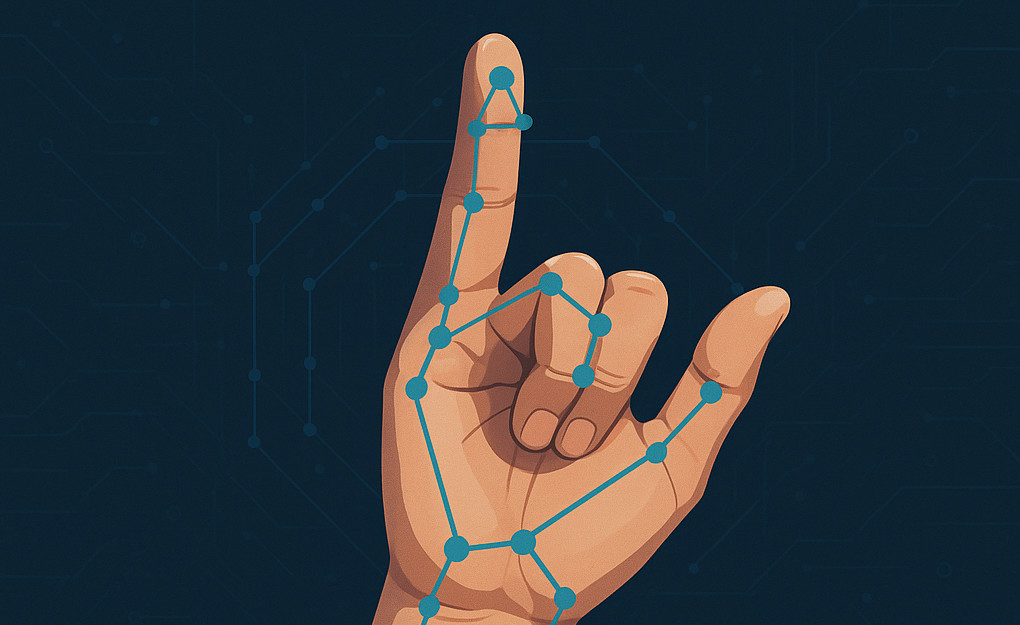
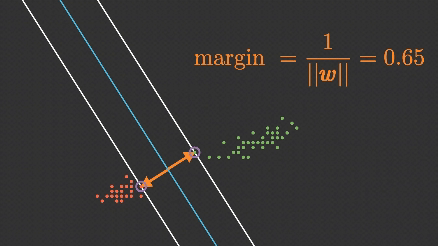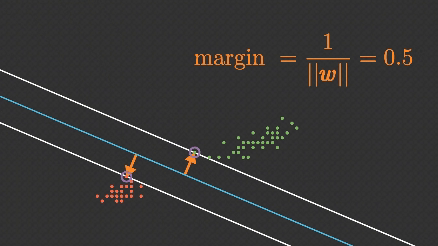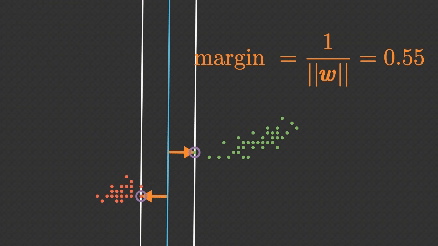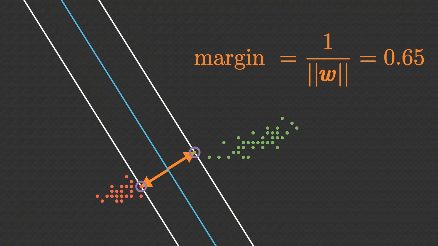A real-time word level sign language recognition system built with Flask, MediaPipe, and deep learning.
A real-time sign language recognition system built with Flask, MediaPipe, and deep learning. The system can recognize word-level sign language gestures in real-time through a web interface, as well as manage a dataset of sign language videos for training.
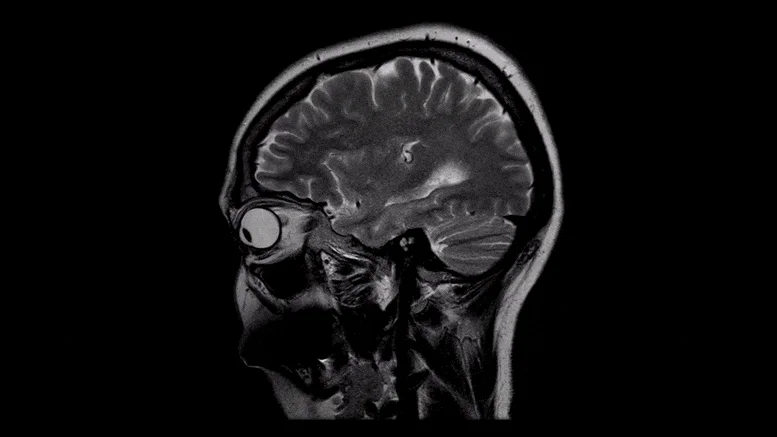
This project aimed to build a Convolutional Neural Network based deep learning model to first identify brain tumors and then classify them as Benign Tumors, Malignant Tumors or Pituitary Tumors.
This project aimed to build a Convolutional Neural Network based deep learning model to first identify brain tumors and then classify them as Benign Tumors, Malignant Tumors or Pituitary Tumors.
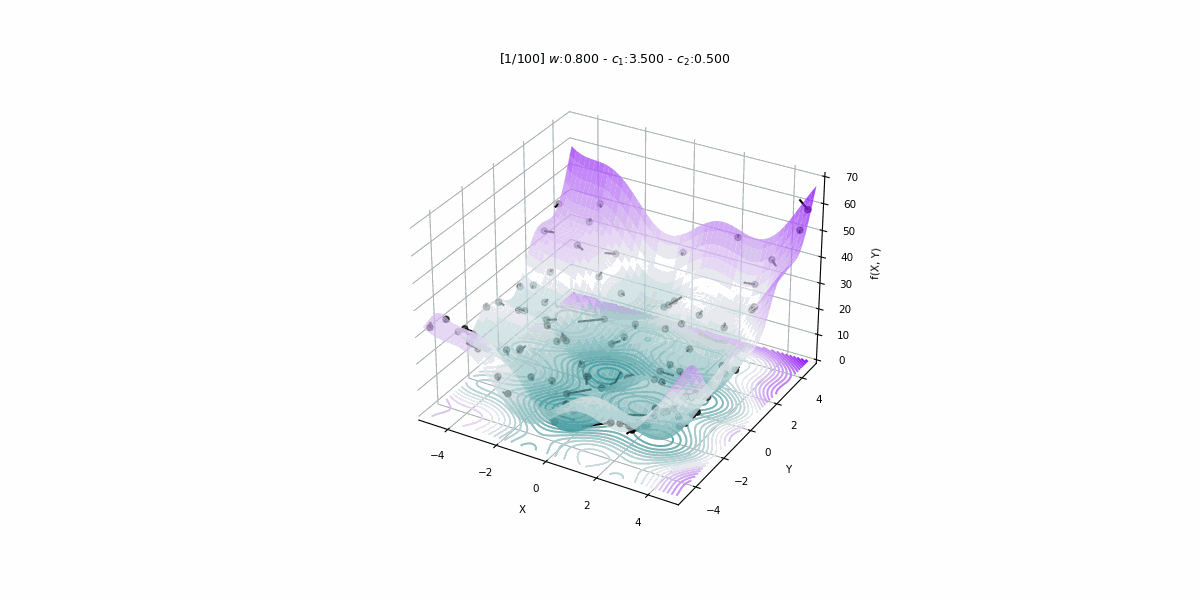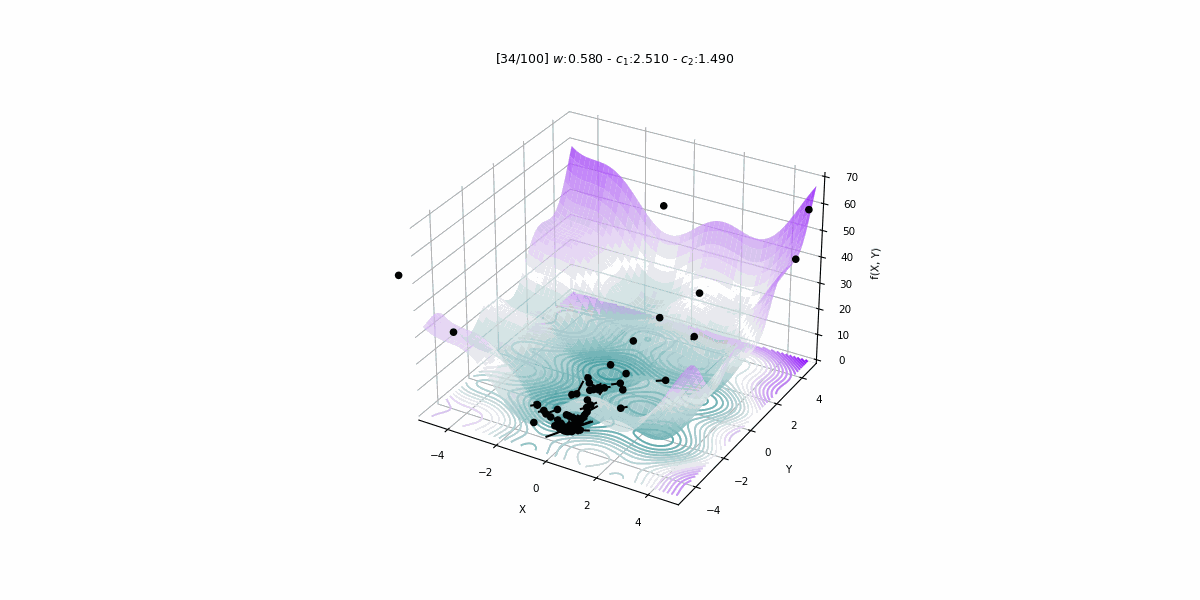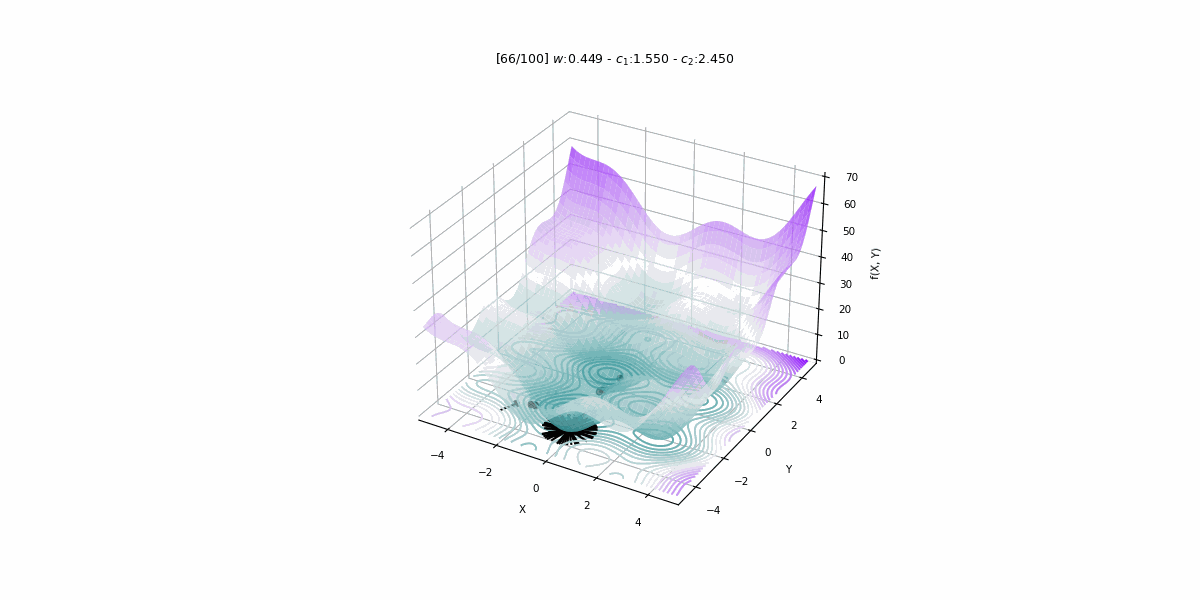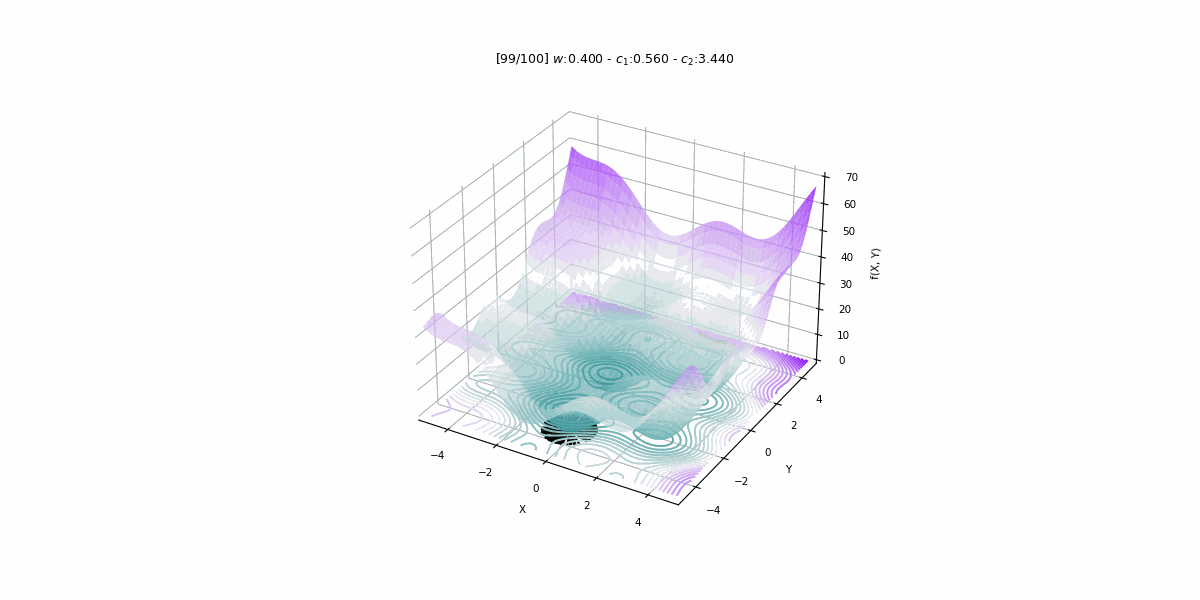
Bu projede 1979 – 2015 yıllarına ait veriler kullanılarak Türkiye’nin enerji talebini PSO algoritması ile tahmin eden doğrusal bir tahmin modeli geliştirilmiştir.
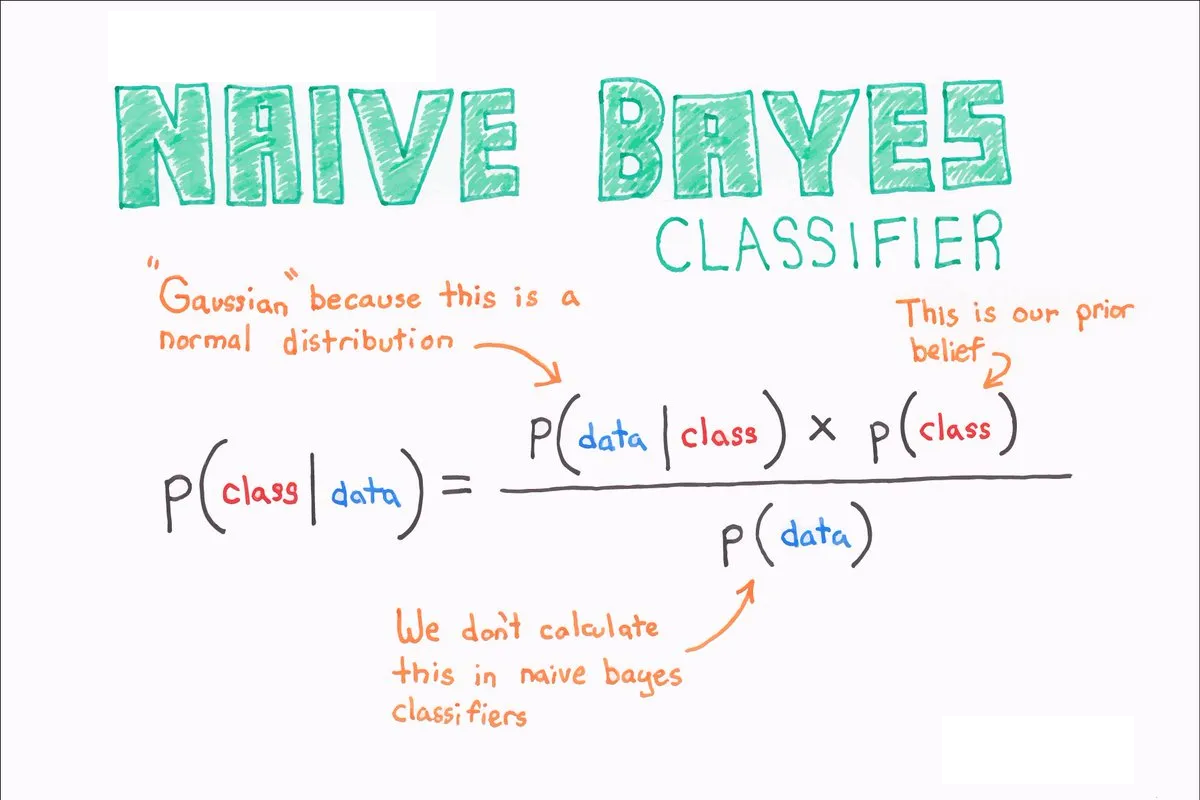
Naive Bayes algoritması, olasılık teorisine dayalı, basit ve hızlı bir makine öğrenme algoritmasıdır. Özellikle sınıflandırma problemlerinde sıkça kullanılır. Algoritmanın temel prensibi, Bayes Teoremi’ne dayanarak sınıf olasılıklarını tahmin etmektir.
Naive Bayes, bağımsızlık varsayımı (naive assumption) yapar; yani bir veri kümesindeki özelliklerin birbirinden bağımsız olduğunu kabul eder. Bu, gerçek dünyada nadiren doğru olsa da, birçok problemde etkili sonuçlar verir.
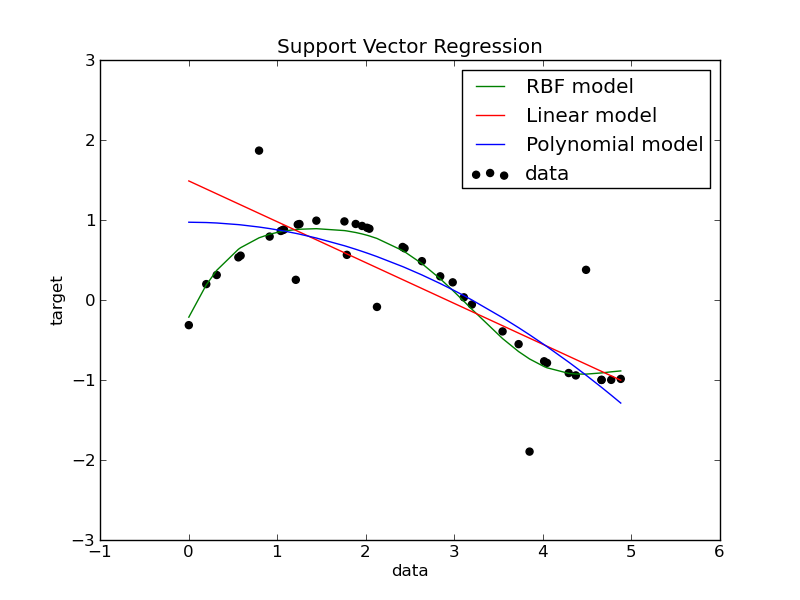
Support Vector Machine (SVM) algoritması, makine öğrenmesinde hem sınıflandırma hem de regresyon problemlerinde yaygın olarak kullanılan, özellikle küçük ve orta boyutlu veri setlerinde etkili olan güçlü bir algoritmadır.
SVM, genellikle doğrusal olarak ayrılabilir verilerde kullanılsa da, doğrusal olmayan verilerde de çalışabilmek için kernel yöntemleriyle genişletilebilir.
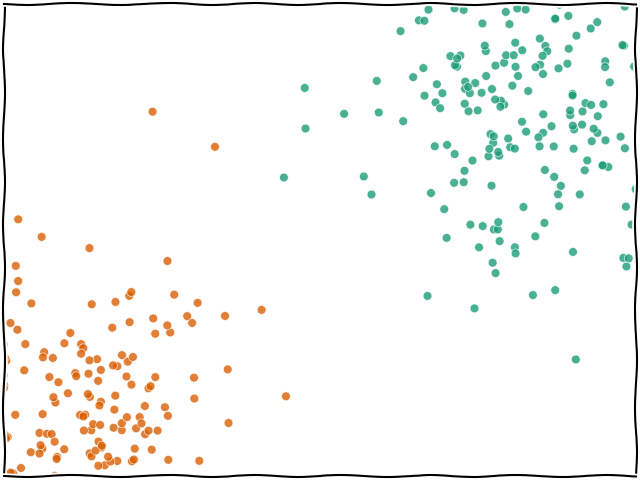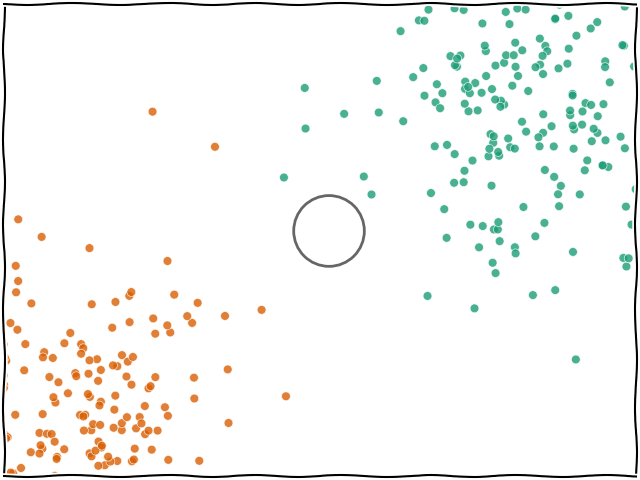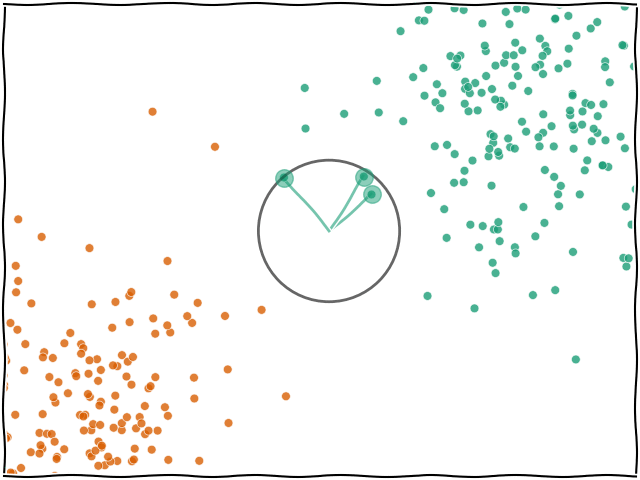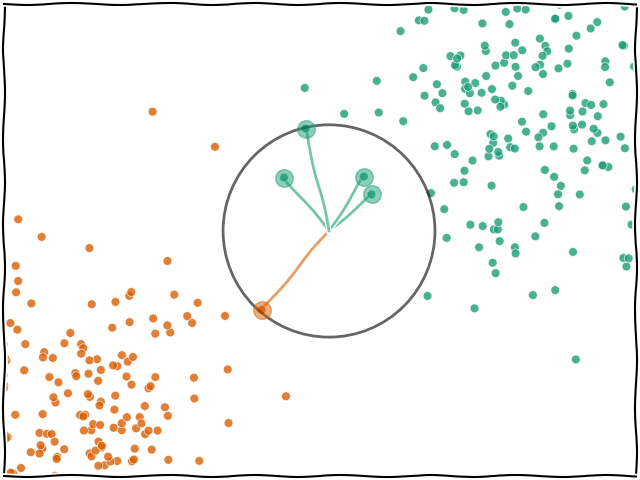
K-NN En Yakın Komşu (K-Nearest Neighbors) algoritması, gözetimli öğrenmeye dayalı ve temelde sınıflandırma veya regresyon problemlerinde kullanılan basit ve sezgisel bir algoritmadır. K-NN, bir veri noktasının sınıfını belirlemek için veri uzayındaki diğer noktalarla olan mesafelerini kullanır.
K-NN, yeni bir veri noktasını sınıflandırmak için eğitim veri kümesindeki en yakın K komşuyu dikkate alır. Bir veri noktasına en yakın K komşunun sınıflarına bakarak yeni veri noktasının hangi sınıfa ait olduğu tahmin edilir. Algoritma, eğitim süreci sırasında bir model oluşturmaz, sadece mevcut veri noktalarını saklar ve tahmin yaparken bu noktalar arasındaki mesafeyi kullanır.
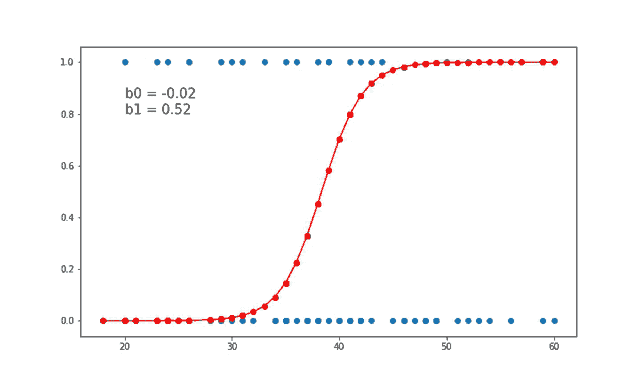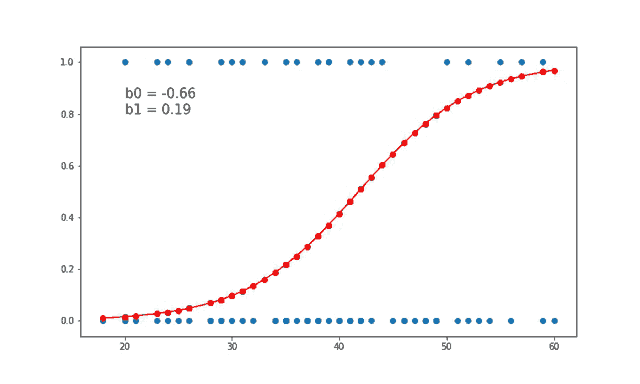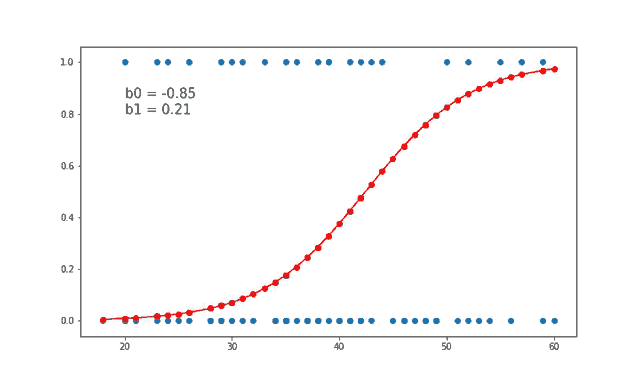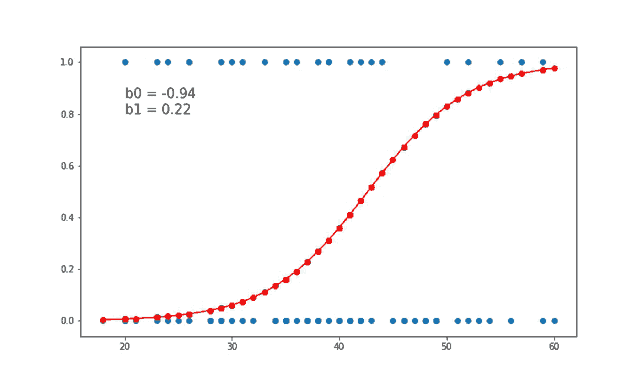
Logistic regression, basit yapısı ve açıklanabilirliği nedeniyle makine öğrenmesi uygulamalarında sıkça tercih edilen bir algoritmadır. Temel sınıflandırma problemlerinde etkili bir çözümdür ve daha karmaşık modellerin anlaşılmasında temel bir yapı taşı olarak görev yapar.
Logistic regression, makine öğrenmesinde kullanılan en temel sınıflandırma algoritmalarından biridir. Lineer regresyon ile benzer temellere dayansa da, logistic regression sınıflandırma problemleri için uygundur. Özellikle iki sınıf (binary) arasındaki ayrımı yapmak için kullanılır, ancak birden fazla sınıf için de genişletilebilir (multinomial logistic regression).
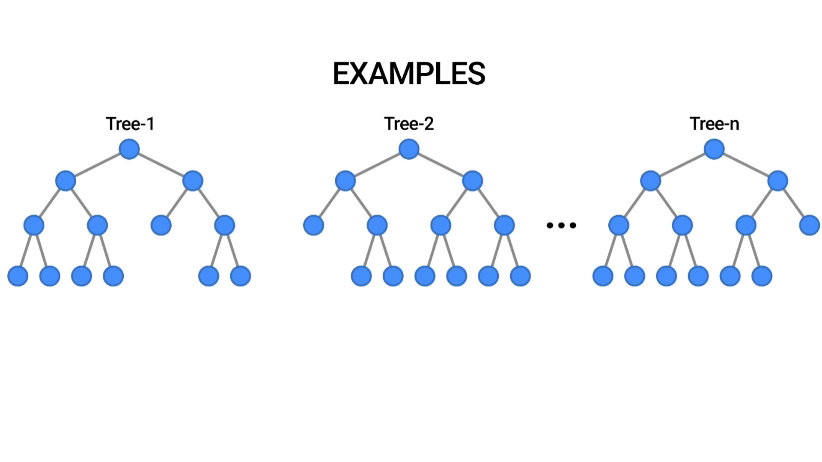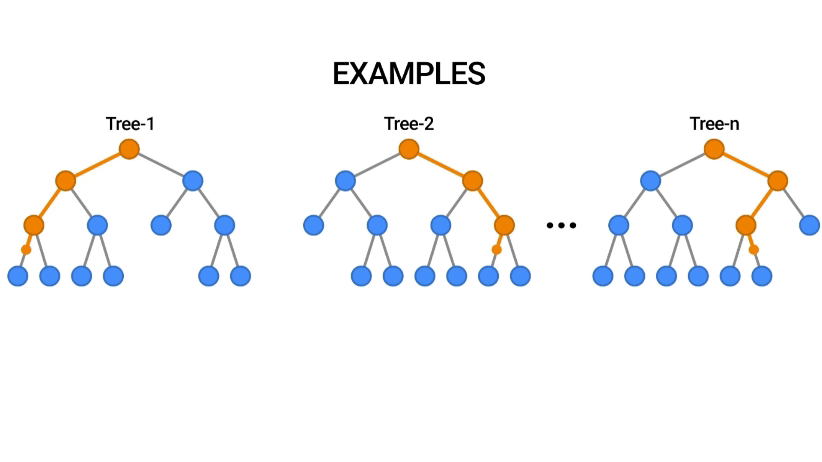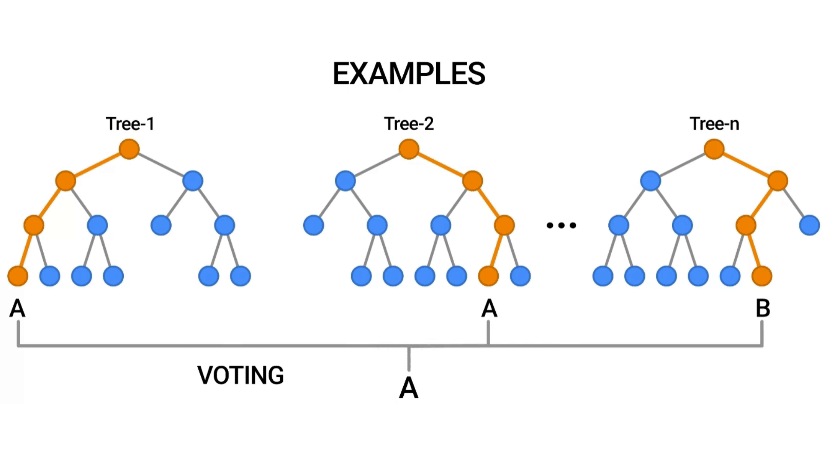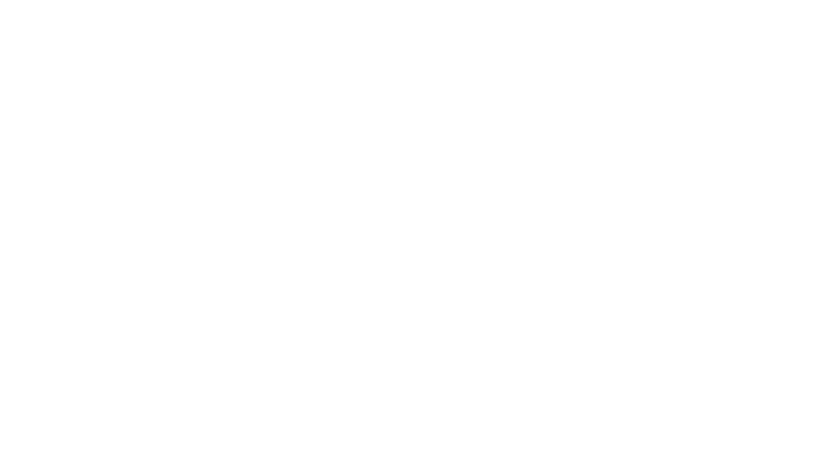
Random Forest, güçlü bir algoritma olup, genellikle yüksek doğruluk oranları sağlar ve birçok uygulamada tercih edilen bir yöntemdir.
Random Forest, makine öğrenmesinde kullanılan popüler bir ensemble (topluluk) öğrenme yöntemidir. Bu algoritma, birden fazla karar ağacı modelinin bir araya getirilmesiyle oluşturulur ve genellikle sınıflandırma ve regresyon problemlerinde kullanılır.
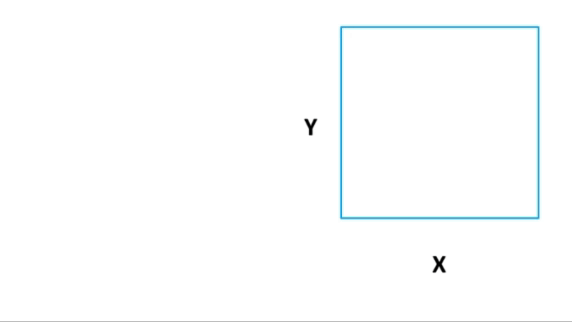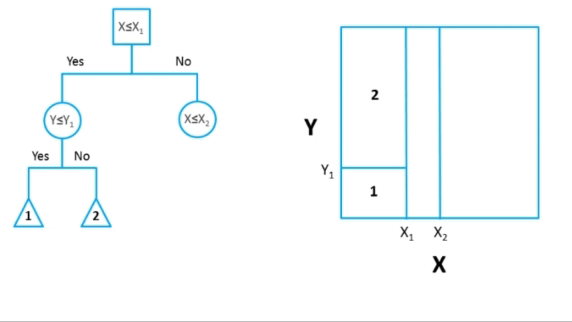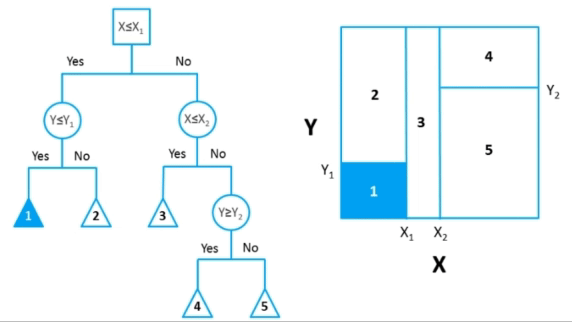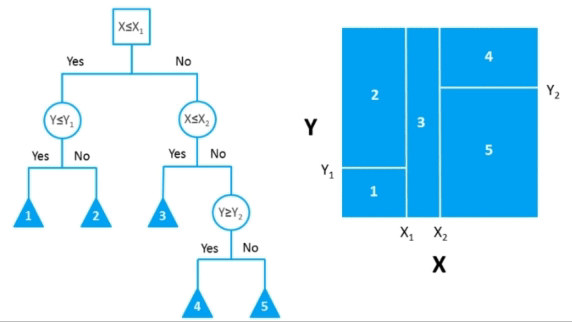
Karar ağaçları (Decision Trees), makine öğrenmesinde yaygın olarak kullanılan bir denetimli öğrenme algoritmasıdır. Hem sınıflandırma hem de regresyon problemlerinde kullanılabilirler.
Karar ağaçları, veriyi dallara ayırarak kararlar verir. Ağaç yapısı, kök düğümden (root) başlayarak, her düğümde bir özelliğin (feature) değeri üzerinden bir karar alır ve bu karara göre dallanarak ilerler. Son düğümler (yaprak düğümler) ise sınıflandırma veya regresyon sonuçlarını temsil eder.